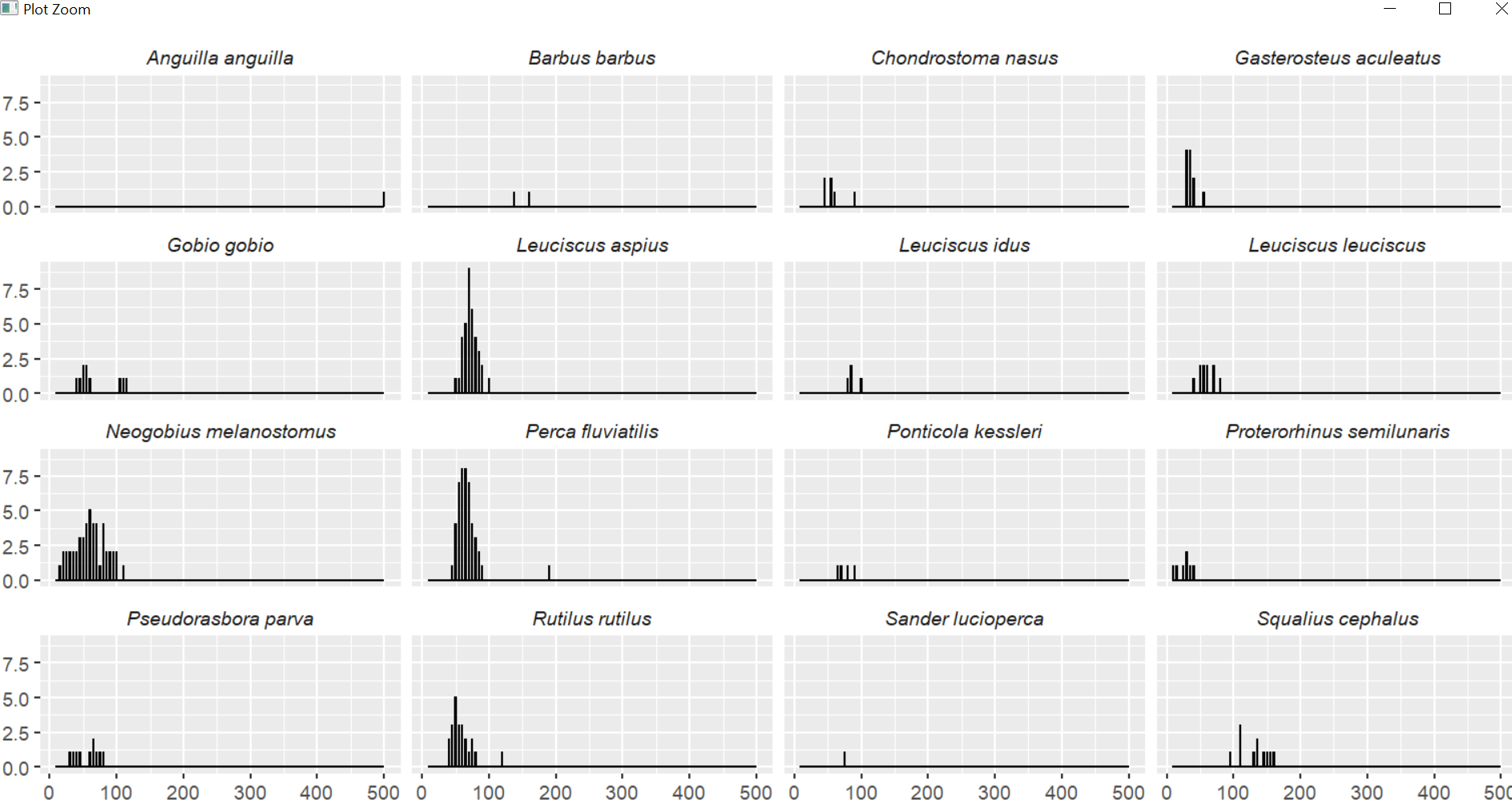
No, it's not percentages. It's just that the number of observation in one group is ~1/16th of the total number, so if p had an axis of 1-50, with the facet wrap you'd have an axis of ~1-3 (actually a bit more since the observations are not totally uniform).
A way to get a feeling for that is to change N in the reprex code below:
library(tidyverse)
N <- 50
data = tibble(length_mm = rpois(16*N, lambda = 50),
latin = rep(LETTERS[1:16], each = N))
p <- ggplot(data, aes(x = length_mm, fill = latin)) +
geom_histogram( binwidth=0.5, color="black", fill="black")
p
p+ facet_wrap(~latin , scales = "fixed")+
ylab(NULL)+ # remove the word "count"
theme( strip.background = element_blank(),
strip.text.x = element_text(face = "italic"),
legend.position="none"
)
What happens for N <- 5000?
Also you might be interested in geom_density() if you want to plot all of these on the same graph with different colors:
p <- ggplot(data, aes(x = length_mm, fill = latin)) +
geom_density(alpha = .2)
p
Still hard to read with 16 groups, but if there is a grouping that makes sense (e.g. by Genus) it could be better to have, say, 3 facets with 5 species each.
And since I'm already writing too much, I'm sure you're aware, but I would be very wary of a histogram with 1 single observation (as seems to be the case with A anguilla or S lucioperca).