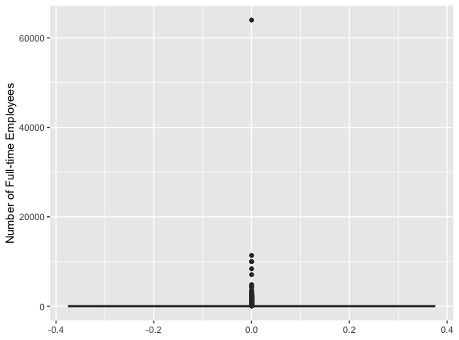
This is for my assignment, where I have been given a dataset (Survey Methodology for Enterprise Surveys - World Bank Group) and assigned to predict the businesses with growth potential. However, there are some extreme numerical values. The "employee" variable refer to the number of full-time employees.
Below is the box plot:
The question given by the lecturer is: "Check the dataset for outliers and replace or delete those values as appropriate. You must provide justifications for your cleaning strategies and discuss the potential issues associated with your chosen strategies."
This is where the domain knowledge circle of the three Venn diagram circle of the definition of data science comes in. Where does the data come from? What businesses do the data represent? If this is a sample of 50 businesses in your local shopping area, then that 64000 point is likely an error. If it is a sample of all possible businesses, then it may not be an error, although for reference the giant insurer Prudential only has 42000 employees. At any rate, the 64000 point is probably unrepresentative of the data and unhelpful to your study. I would delete it.
Ah, then 6400 is possible, and would not even be the maximum, although the mean of 88 and third quartile of 72 are small relative to 6400.
It would not be unreasonable to replace it with 6400. Another possibility is to set it equal to Third Quartile + 3*(Third Quartile - First Quartile) called Tukey's fences.