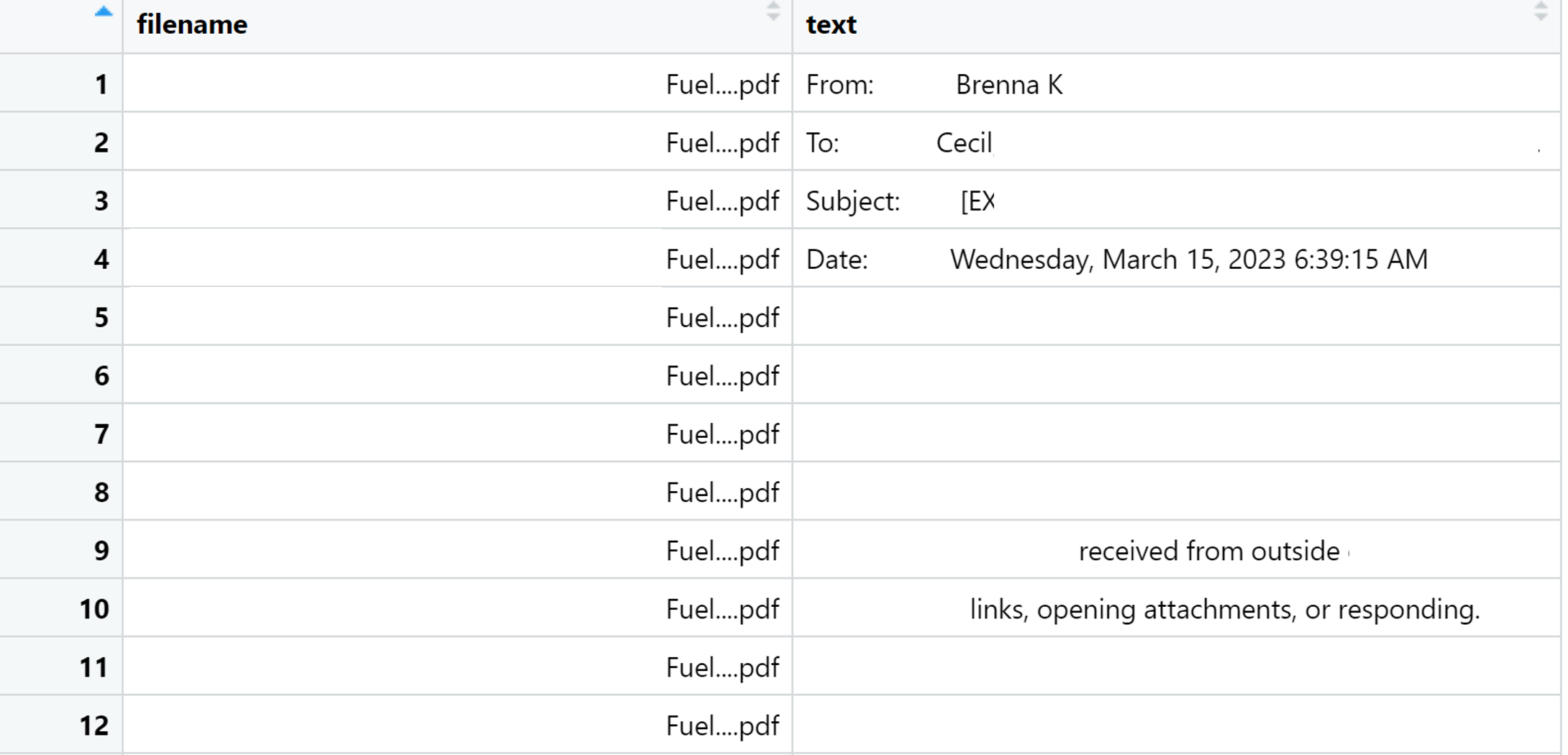
I have some code setup to work through many files (individual PDFs) in a folder. They are all simple email exports into PDFs. I am having a hard time figuring out how to actually extract some of the text. I was able to use stringr to detect strings but cant figure out how to actually extract what I want and save it to a dataframe.
I would like to extract the name after the word "From:", the entire date string after the word "Date" and test if there are attachments (Y/N). And lastly, I would like the entire text from the body of the email to be captured in the column "text" in my dataframe. I have tried a few different ways for extracting the name and date which you will see under the comment "Extract who sent email and the date".
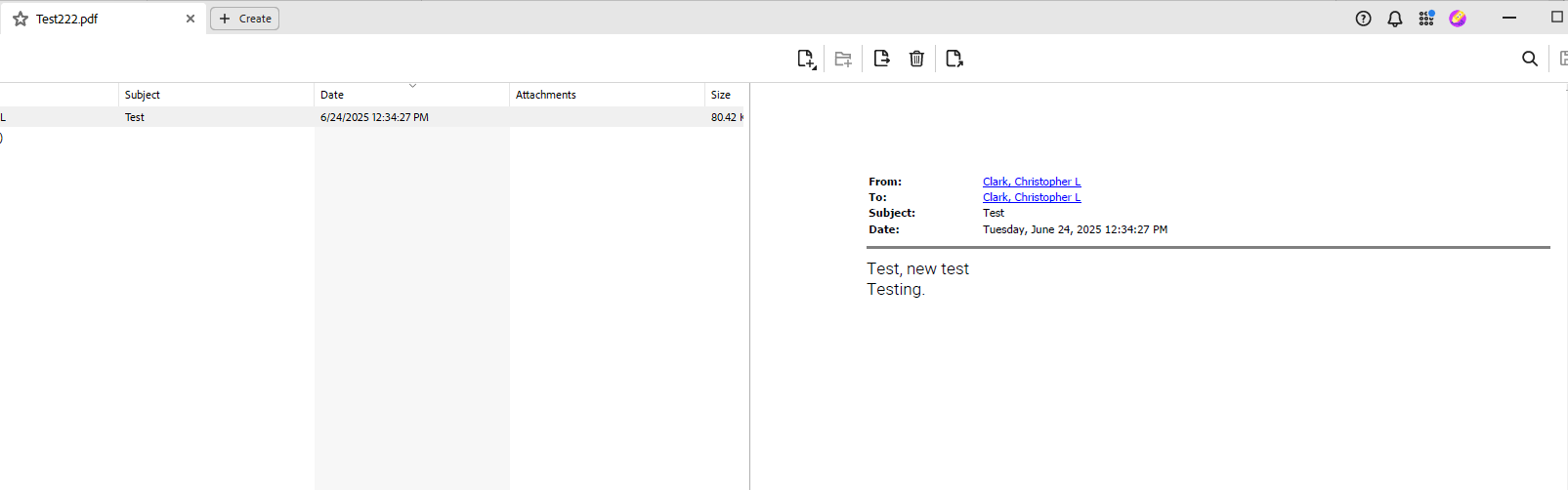
This Email example ideally would result in one row of a data frame such as:

library(pdftools)
library(purrr)
library(dplyr)
library(stringr)
# Set the working directory to where the PDF files are located
pdf_path <- "/Desktop/test"
# List all PDF files in the directory
file_list <- list.files(path = pdf_path, pattern = "*.pdf", full.names = TRUE)
# Define the regular expressions for extracting date and name
rx_date <- "Date:.*\\\\K\\\\b[0-9]{1,2}\\\\s[a-zA-Z]+\\\\s[0-9]{4}\\\\b"
rx_name <- "From:.*\\\\K\\\\b[_a-z0-9-]+(?:\\\\.[_a-z0-9-]+)*@[a-z0-9-]+(?:\\\\.[a-z0-9-]+)*\\\\.[a-z]{2,4}\\\\b"
# Function to extract text from PDF and save to Excel
extract_pdf_to_excel <- function(file_list) {
# Read the PDF file
pdf_text <- pdf_text(file_list)
# Split the text into lines and full text
lines <- unlist(strsplit(pdf_text, "\n"))
full_text <- paste(pdf_text, collapse = " ")
# Extract who sent the email and the date
name <- str_detect(full_text,
pattern ="From:.*\n.*")
date <- str_detect(full_text,
pattern = "Date:.*\\\\K\\\\b[0-9]{1,2}\\\\s[a-zA-Z]+\\\\s[0-9]{4}\\\\b")
# Extract the text from the PDF into one text string, make lower case for case insensitive search of terms
#full_text <- paste(pdf_text, collapse = " ")
full_textL <- tolower(full_text)
# Check for presence of attachments
has_attachments <- grepl("attachment", "attachments", full_textL)
has_attachments <- ifelse(has_attachments, "Yes", "No")
# Create a data frame from the lines
resultdf <- data.frame(filename = basename(file_list), name = name, date = date, attachment = has_attachments, text = full_text, stringsAsFactors = FALSE)
return(resultdf)
}
result_list <- map(file_list, extract_pdf_to_excel)
# Combine all processed data into a single df
results_df <- bind_rows(result_list, .id = "file_id")