Edit: The issue seems to be with saving .rds files within a drake pipeline, and unrelated to ggplotly. Apologies.
Original post (where I mistook this for a plotly issue):
Hi there,
I have a project where I've been using plotly::ggplotly() to turn ggplots into interactive graphics for online use in Shiny apps. However, it soon became evident that this resulted in some outrageously large files and objects, resulting in both an unnecessarily slow and unnecessarily large shiny app.
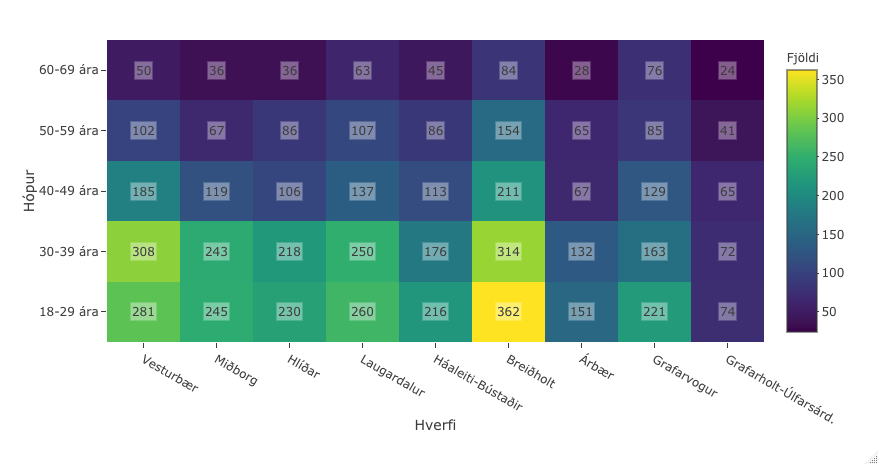
As we have dozens and dozens of graphs that we display in the Shiny app, a plot object is only read from an .rds file when needed, on the fly. This makes the ggplotly objects pretty much unusable as a simple barchart that is 20KB as an .rds file created using plotly, can be 250MB as an .rds file created using ggplot2 and then ggplotly. Below is an example of this behaviour with a heatmap. In short the average plotly-created file/object is 1/1000 the size of the corresponding ggplotly-created file/object.
Edit: I now realise this also happens for regular plotly objects. The two examples below differ in the sense that the smaller is not created within a drake pipeline, while the larger is created within a drake pipeline.
lobstr::obj_size(my_plotly_heatmap)
# 125,840 B
lobstr::obj_size(my_ggplotly_heatmap)
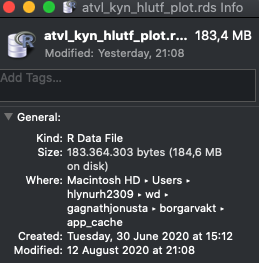
# 145,767,184 B
I'd love to be able to use the ggplotly approach as a lot of these graphics have already been prepared as ggplots for a report. So my question is whether there are some obvious things that I can access in the ggplotly object to cut down the size? (Font information comes to mind, are there raster graphics being stored but not printed? What explains these massive objects?). Are there any guides on this or how-to blogs? I can't seem to find any.
I'm starting to get the sense this might have to do with ggplot2 plot environments, and the fact that these files are created within a massive drake pipeline. But honestly don't know. Just learning about the plot environments trying to google this. I tried recreating the ggplotly heatmap in a fresh session and that results in a 2.6MB .rds file. So that's ~1/50th of the files created within the drake pipeline.
So this is something I likely have to fix before turning the ggplot plot into a plotly object using plotly::ggplotly(), right?
Thanks for the reply. I should probably raise an issue. But I don't know if this is something I should be looked at from the drake point of view, or from the plotly point of view.
@cpsievert and @wlandau (I hope it's ok if I tag you here), could you possibly weigh in on whether this should be considered an issue, and if so, whether it is possibly a drake issue or a plotly issue.
Additional info:
I should add that this is not just an issue with ggplotly but also other plotly objects. This simple plotly barchart:
In drake, this came up at https://github.com/ropensci/drake/issues/882 and https://github.com/ropensci/drake/issues/1258. Unfortunately, there is nothing drake can do at this point to reliably reduce the size of objects from ggplot2 and plotly that hang onto large objects from calling environments. If it ever becomes possible to decouple large datasets without breaking the plot object (maybe with a specialized serialization method) I will consider specialized storage formats for plots, e.g. target(format = "ggplot2") and target(format = "plotly").
Thanks so much for replying Will (and thanks once again for an incredible package). Is the solution for me then, at least for the time being, just saving the .rds files in question outside of the drake_plan as the calling environment is close to empty with a clean session?
Thanks, Carson! I will recommend this to drake users who run into this problem. From there, they can choose a serialization format drake already supports, e.g. target(plotly_object, get_plot(), format = "qs").
@Hlynur, another workaround could have been htmlwidgets::saveWidget(my_plotly, drake::file_out("my_plotly.html"), selfcontained = TRUE). For ggplot2 objects that get too big, an equivalent workaround with ggsave() and PNG files will still allow you to have plots as targets in the plan. In other cases like lm() objects, you can swap in stats::lm() for biglm::biglm().