Thank you for your feedback, @M_AcostaCH! My apologies for not doing so the first time.
The result of dput(pA_CF_pre[ 1:30, ]) is:
structure(list(word = structure(c(197L, 86L, 62L, 70L, 125L,
128L, 62L, 63L, 11L, 168L, 19L, 6L, 9L, 106L, 72L, 67L, 68L,
66L, 6L, 6L, 85L, 146L, 164L, 12L, 72L, 6L, 86L, 80L, 156L, 124L
), .Label = c("", "arm", "away", "backyard", "bathroom", "bed", "bedroom", "black", "blanket", "blankets", "blue", "breath", "breathe", "breathing", "brown", "building", "bus stop", "cafeterias", "camera", "car", "cars", "cat", "class", "classrooms", "cleaning", "cleanliness", "clinic", "closet", "clothing", "college", "comfortable", "construction", "crawl", "cry", "curtain", "dance", "diet", "disability", "doctor", "dog", "drink", "educate", "educating", "education", "empty", "everywhere", "exercising", "exhale", "facts", "fiction", "fight", "fire", "firepit", "fish", "floor", "flooring", "food", "fridge", "friends", "garden", "glance", "grabbing", "grasping", "grass", "green", "guys", "hand", "headphones", "heat", "holding", "home", "hospital", "hot", "hungry", "inhale", "inside", "itch", "jeans", "jump", "jumping", "kitchen", "labor", "laugh", "lawn", "lay", "laying", "learning", "leash", "left", "leg", "library", "living room", "look", "lost", "loud", "medication", "memorizing", "mirror", "missed", "missing", "mouth", "move", "mushrooms", "neighbors", "new", "nurse", "old", "orange", "orbit???", "organizing", "oven", "overwhelming", "pacing", "pads", "painting", "pantry", "paving", "pedestrians", "people", "pillow", "pillows", "pills", "planning", "polo?", "pushing", "quiet", "raccoons", "reaching", "red", "relax", "right", "round", "run", "running", "scholarship", "school", "seizure", "shirt", "shooting", "shout", "shouting", "shower", "silent", "sink", "situating", "skirball", "slow",
"smell", "smile", "socks", "sore", "sorting", "speak", "speaking",
"squirrels", "standing", "stare", "street", "streetcar", "streets",
"stretch", "students", "studying", "swallow", "sweater", "swim",
"switch", "table", "talk", "talking", "tall", "taught", "tired",
"towards", "towel", "traffic", "traveled", "tray", "trees", "truck",
"trucks", "trying", "twitch", "university", "unsaid", "unsure",
"van", "vans", "vegetables", "vehicle", "vehicles", "violence",
"vocabulary", "walk", "walking", "whisper", "whispering", "white",
"wine", "wood", "work", "workers", "working", "writing", "yell",
"yellow"), class = "factor"), phase = c("pre-story", "pre-story",
"pre-story", "pre-story", "pre-story", "pre-story", "pre-story",
"pre-story", "pre-story", "pre-story", "pre-story", "pre-story",
"pre-story", "pre-story", "pre-story", "pre-story", "pre-story",
"pre-story", "pre-story", "pre-story", "pre-story", "pre-story",
"pre-story", "pre-story", "pre-story", "pre-story", "pre-story",
"pre-story", "pre-story", "pre-story"), order = c(291L, 292L,
293L, 294L, 295L, 296L, 297L, 298L, 299L, 1L, 2L, 3L, 4L, 5L,
6L, 7L, 8L, 9L, 10L, 31L, 32L, 33L, 34L, 35L, 36L, 37L, 38L,
39L, 40L, 21L), raters = c("CF", "CF", "CF", "CF", "CF", "CF",
"CF", "CF", "CF", "CF", "CF", "CF", "CF", "CF", "CF", "CF", "CF",
"CF", "CF", "CF", "CF", "CF", "CF", "CF", "CF", "CF", "CF", "CF",
"CF", "CF"), ratings = c(1, 1, 1, 1, 1, 1, 1, 1, 1, 4, 1, 2,
1, 1, 1, 1, 1, 3, 2, 2, 2, 1, 2, 3, 1, 2, 2, 1, 2, 1)), row.names = c(1L,
6L, 11L, 16L, 21L, 26L, 31L, 36L, 41L, 196L, 201L, 206L, 211L,
216L, 221L, 226L, 231L, 236L, 241L, 246L, 251L, 256L, 261L, 266L,
271L, 276L, 281L, 286L, 291L, 296L), class = "data.frame")
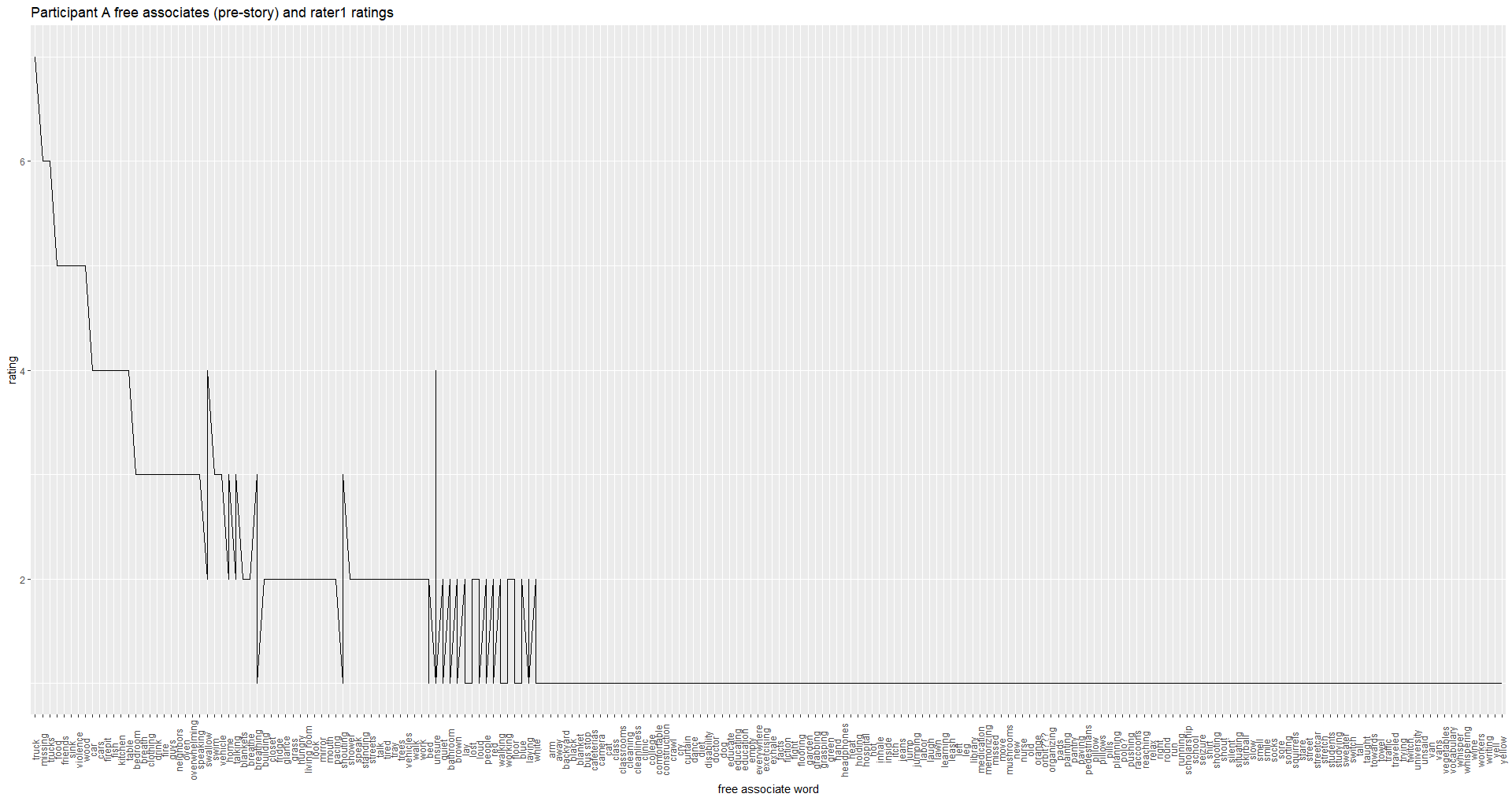
The plot produced with your above code is not exactly what I am looking for. Thank you for your suggestion!
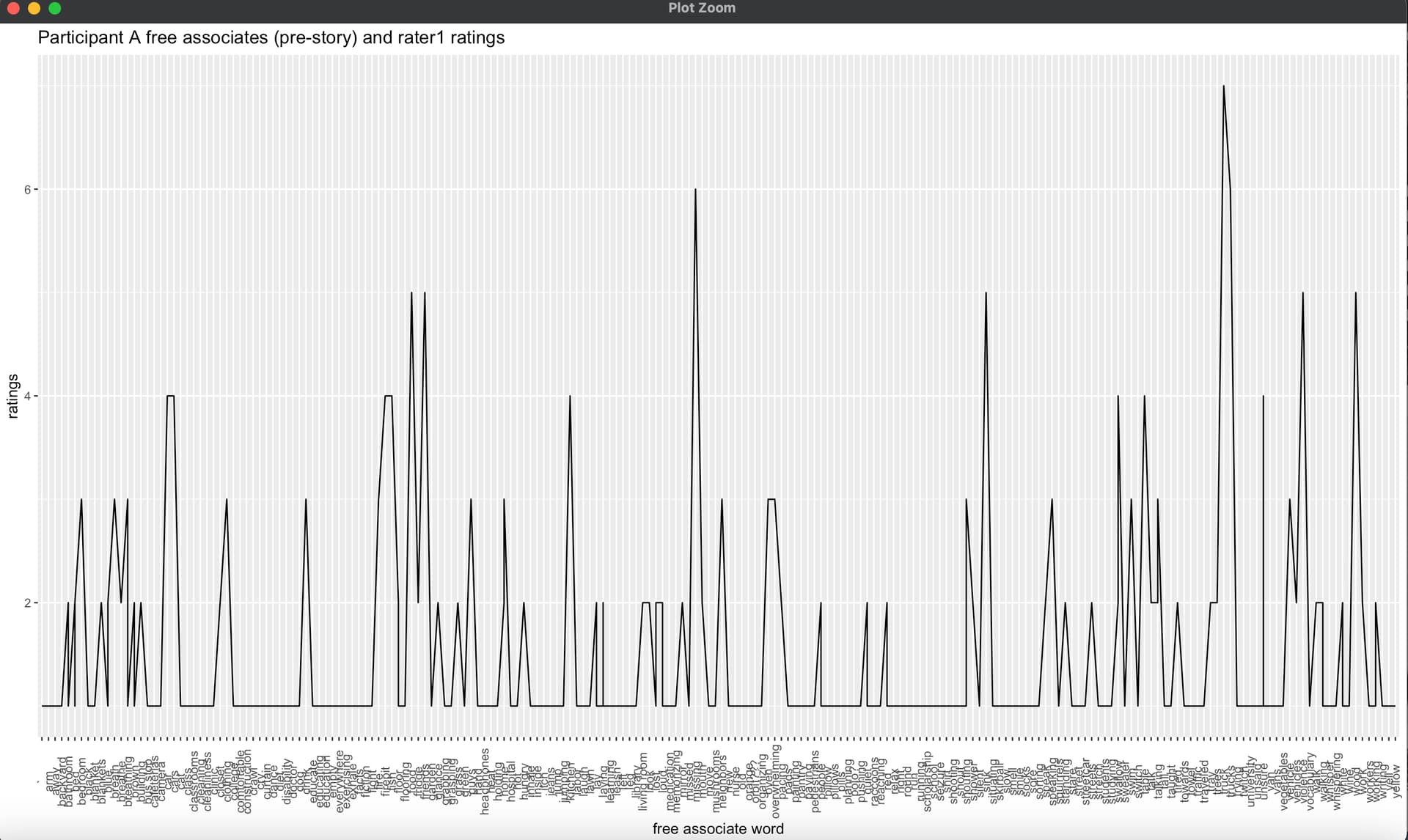
Here is a reprex example of my initial inquiry for the line graph. I attached a link here for a CSV file for the free associate words for my working condition.
library(plyr)
library(Hmisc)
library(ggcorrplot)
library(psych)
library(tidyverse)
library(ggplot2)
library(ggthemes)
library(cowplot)
library(gridExtra)
library(patchwork)
#load csv file for list of free associates
free_associates <- read.csv("[insert csv file]/sample_word.csv")
head(free_associates)
#input order, phase, and raters columns for pre-story condition
order <- c(291:299,1:10,31:40,21:30,111:120,231:240,81:90,11:20,101:110,181:190,121:130,281:290,261:280,51:60,221:230,251:260,161:170,191:210,91:100,141:150,241:250,41:50,211:220,131:140,61:70,171:180,151:160,71:80)
phase <- rep(c("pre-story"),299)
raters <- rep(c("CF"),299)
participant_A <- data.frame(free_associates,phase,raters,order)
#convert CF chr vectors to numeric
participant_A$CF[participant_A$CF == "1 (not at all)"] <- "1"
participant_A$CF[participant_A$CF == "7 (very much)"] <- "7"
participant_A$CF <- as.numeric(sapply(participant_A$CF, as.numeric))
colnames(participant_A)[2] = "rating" #rename CF to ratings
#participant_A$word <- as.factor(participant_A$word) -- not necessary?
free_associates_pre <- ggplot(participant_A, aes(x=as.factor(word), y=rating))+geom_line(group=1)+
theme(axis.text.x = element_text(angle=90, hjust=0.5))+
xlab("free associate word")+
ggtitle("Participant A free associates and rater1 ratings")
free_associates_pre
Looking forward to any further suggestions! Thank you so much.
Kind regards,