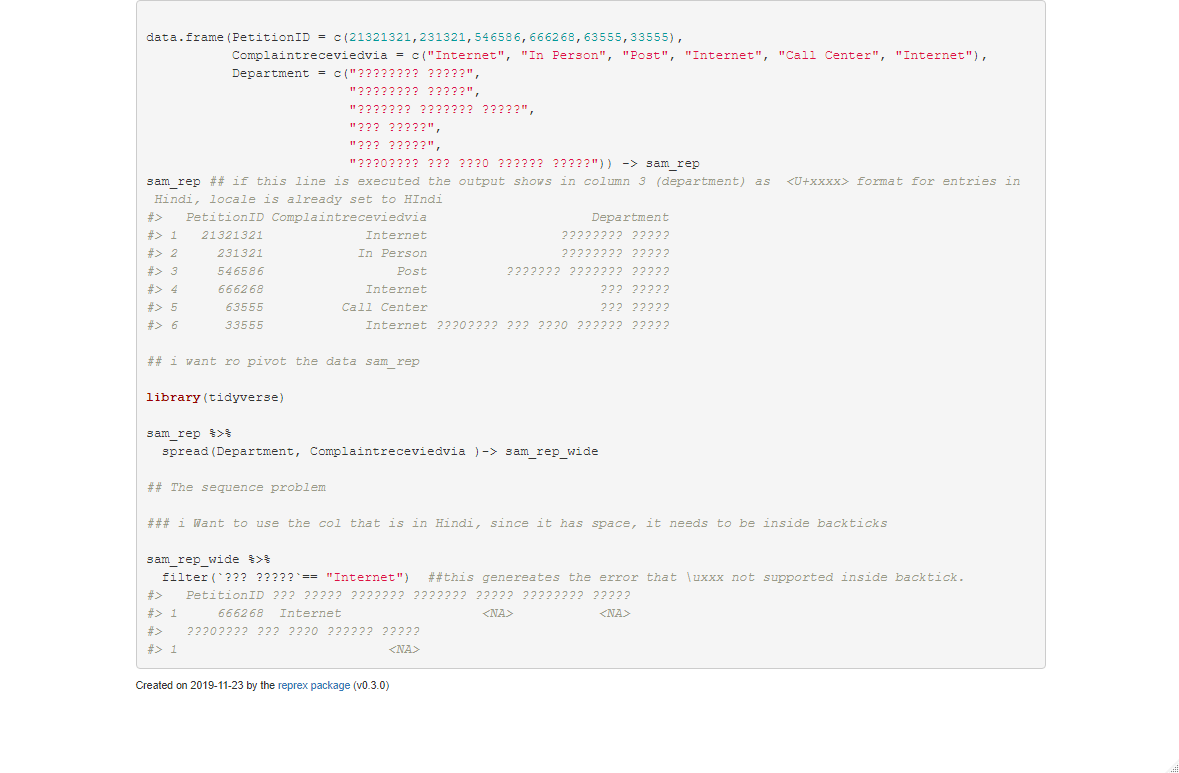
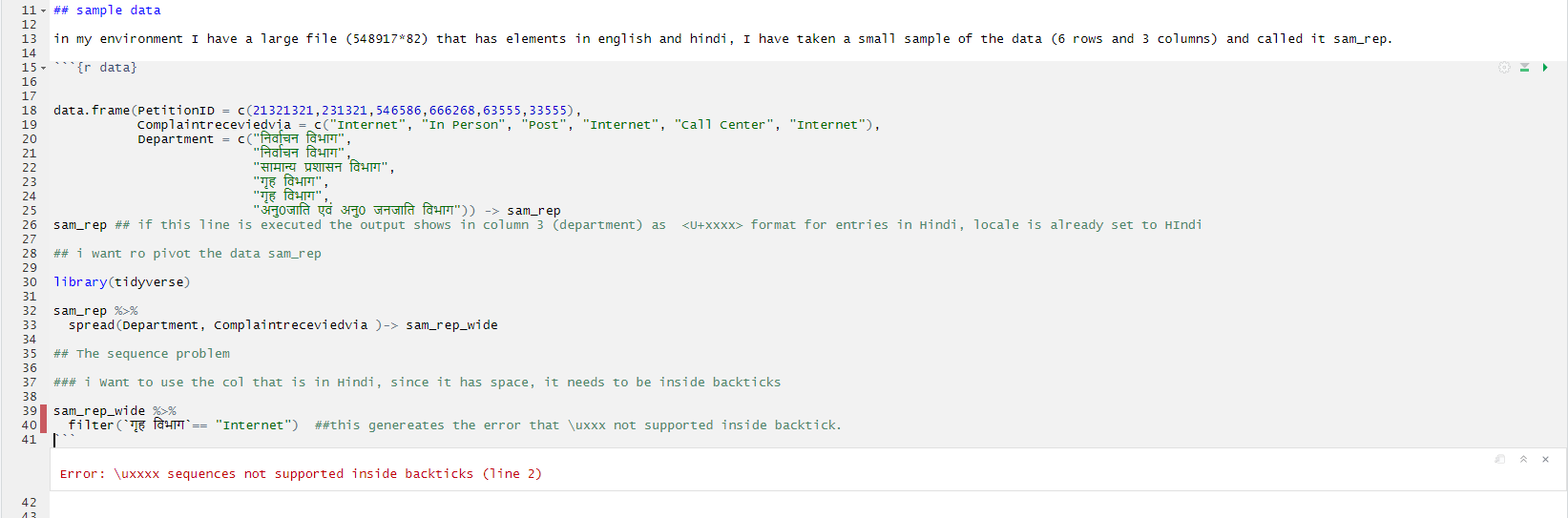
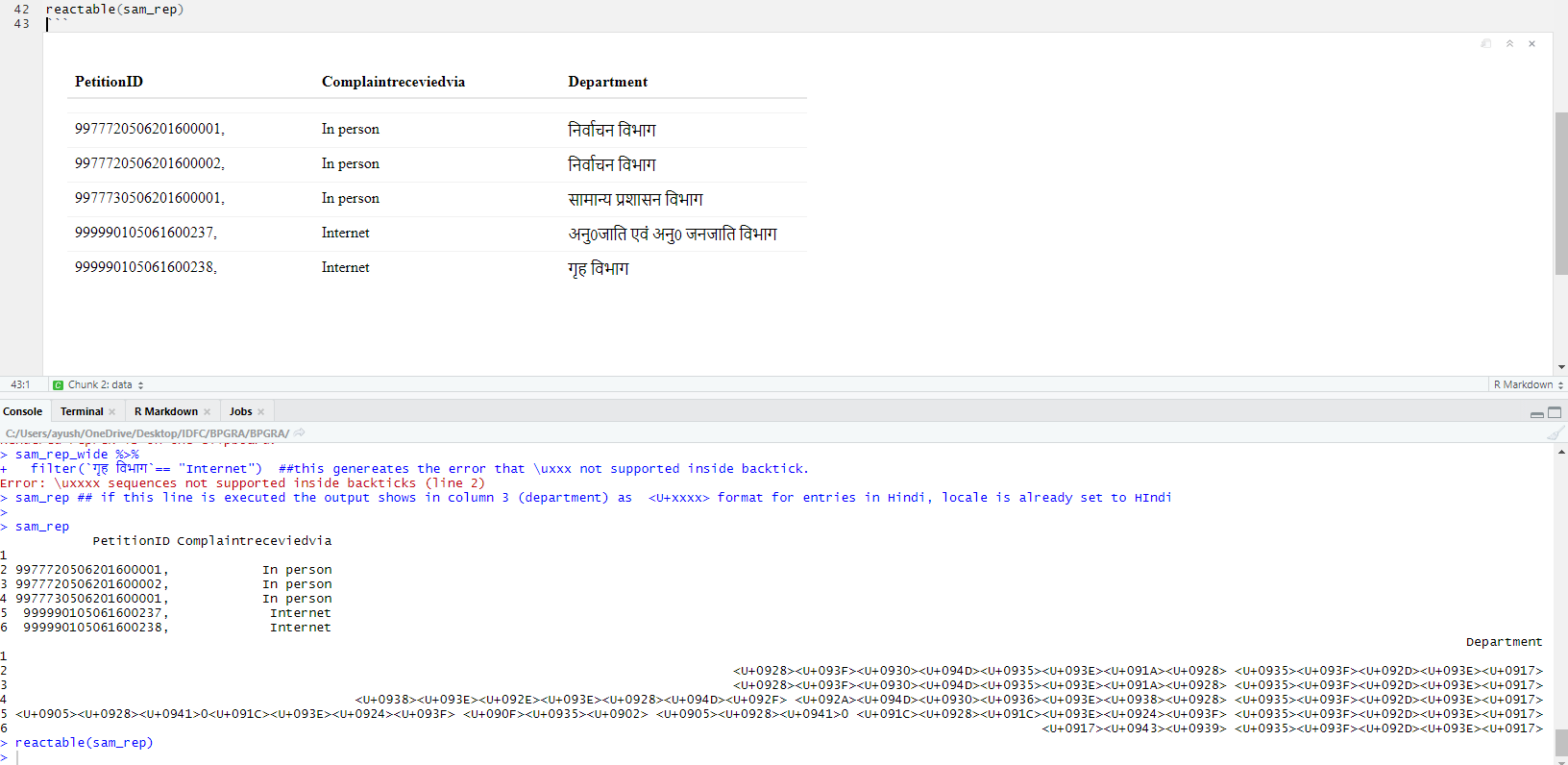
I am trying to run the following lines of code:
ggplot(data = a, aes(a$District, a$ अनु0जाति एवं अनु0 जनजाति विभाग ))+
geom_line()
system generates the following error:
Error: \uxxxx sequences not supported inside backticks (line 1)
following is the session information:
**> sessionInfo()
R version 3.6.1 (2019-07-05)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 18362)
Matrix products: default
locale:
[1] LC_COLLATE=Hindi_India.1252 LC_CTYPE=Hindi_India.1252 LC_MONETARY=Hindi_India.1252 LC_NUMERIC=C LC_TIME=Hindi_India.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] skimr_1.0.7 data.table_1.12.6 forcats_0.4.0 stringr_1.4.0 dplyr_0.8.3 purrr_0.3.3 readr_1.3.1 tidyr_1.0.0 tibble_2.1.3
[10] ggplot2_3.2.1 tidyverse_1.2.1 haven_1.1.0
loaded via a namespace (and not attached):
[1] Rcpp_1.0.3 highr_0.8 cellranger_1.1.0 pillar_1.4.2 compiler_3.6.1 base64enc_0.1-3 tools_3.6.1 zeallot_0.1.0 digest_0.6.22 lubridate_1.7.4
[11] gtable_0.3.0 jsonlite_1.6 evaluate_0.14 lifecycle_0.1.0 nlme_3.1-140 lattice_0.20-38 pkgconfig_2.0.3 rlang_0.4.1 cli_1.1.0 rstudioapi_0.10
[21] yaml_2.2.0 xfun_0.11 withr_2.1.2 xml2_1.2.2 httr_1.4.1 knitr_1.26 generics_0.0.2 vctrs_0.2.0 hms_0.5.2 grid_3.6.1
[31] tidyselect_0.2.5 glue_1.3.1 R6_2.4.1 readxl_1.3.1 rmarkdown_1.17 modelr_0.1.5 magrittr_1.5 scales_1.0.0 backports_1.1.5 htmltools_0.4.0
[41] rvest_0.3.5 assertthat_0.2.1 colorspace_1.4-1 stringi_1.4.3 lazyeval_0.2.2 munsell_0.5.0 broom_0.5.2 crayon_1.3.4
ggplot(data = a, aes(a$District, a$
अल्पसंख्यक कल्याण विभाग))+
Error: \uxxxx sequences not supported inside backticks (line 1)**