Dear people ,
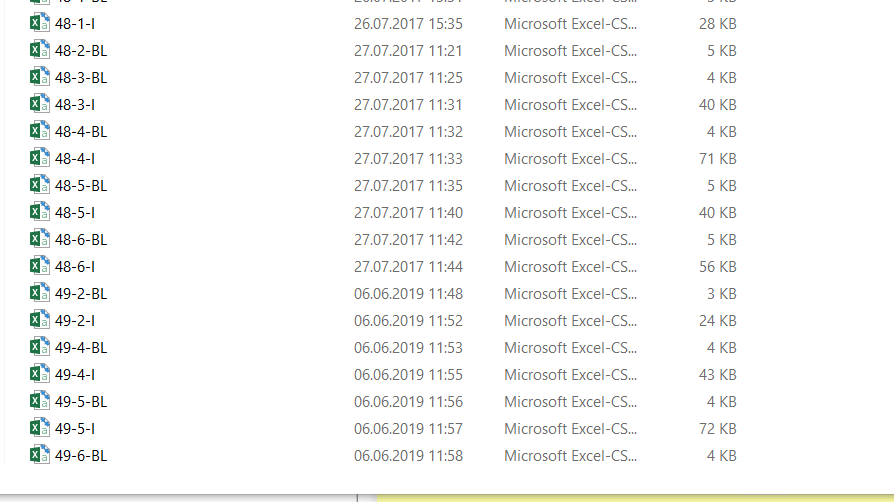
I tried the following part of a syntax with a set of 70 cases and it works for the first 48 cases but gives me the error "undefined colums selected" before case 49 even though the columns are the same as in the 48 cases before.
files <- list.files(pattern = "\.csv")
merged.data<-data.frame(matrix(NA, nrow=0, ncol=7))
names(merged.data)<-c("ID","Session","Phase","Start.Time" ,"End.Time", "C.SCL","T.SCL")
for (i in 1:length(files)){
mydata <- read.csv(files[i])
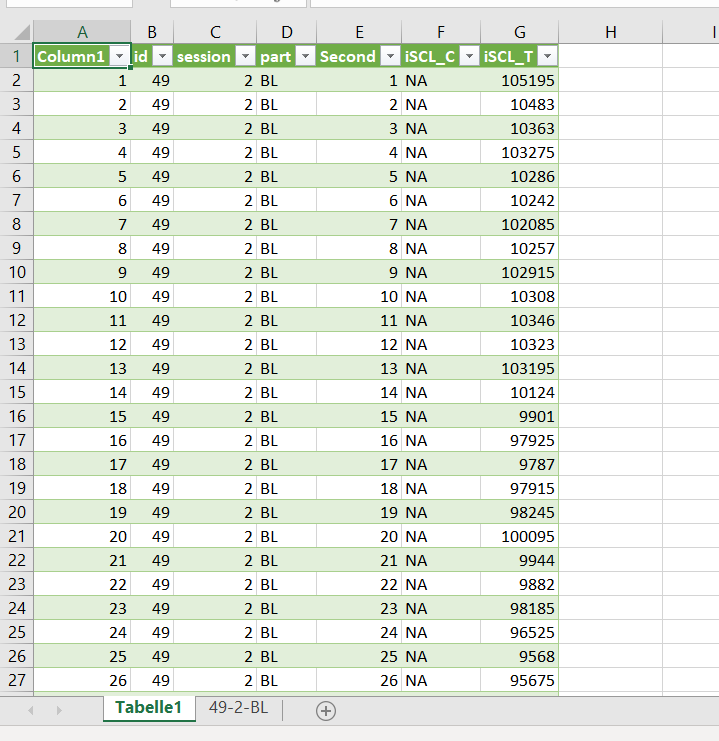
A<-mydata[,2:5]
A$End.Time<-A$Second+1
B<-mydata[,6:7]
mydata2<-data.frame(A,B)
names(mydata2)<-c("ID","Session","Phase","Start.Time" ,"End.Time", "C.SCL","T.SCL")
merged.data<-rbind(merged.data,mydata2)
print(paste("File: ", files[i]," ;", i," out of ",length(files),"(",((i/length(files))*100),"%)",sep=""))
}
Version:1.0 StartHTML:0000000107 EndHTML:0000001720 StartFragment:0000000127 EndFragment:0000001702
`> 1] "File: 48-1-I.csv ;434 out of 664(65.3614457831325%)" [1] "File: 48-2-BL.csv ;435 out of 664(65.5120481927711%)" [1] "File: 48-3-BL.csv ;436 out of 664(65.6626506024096%)" [1] "File: 48-3-I.csv ;437 out of 664(65.8132530120482%)" [1] "File: 48-4-BL.csv ;438 out of 664(65.9638554216867%)" [1] "File: 48-4-I.csv ;439 out of 664(66.1144578313253%)" [1] "File: 48-5-BL.csv ;440 out of 664(66.2650602409639%)" [1] "File: 48-5-I.csv ;441 out of 664(66.4156626506024%)" [1] "File: 48-6-BL.csv ;442 out of 664(66.566265060241%)" [1] "File: 48-6-I.csv ;443 out of 664(66.7168674698795%)"
Error in [.data.frame(mydata, , 2:5) : undefined columns selected`
��P:
Hopefully I provided you with enough information. I appreciate every hint concerning my potential error.
Thank you in advance and best regards
Andreas