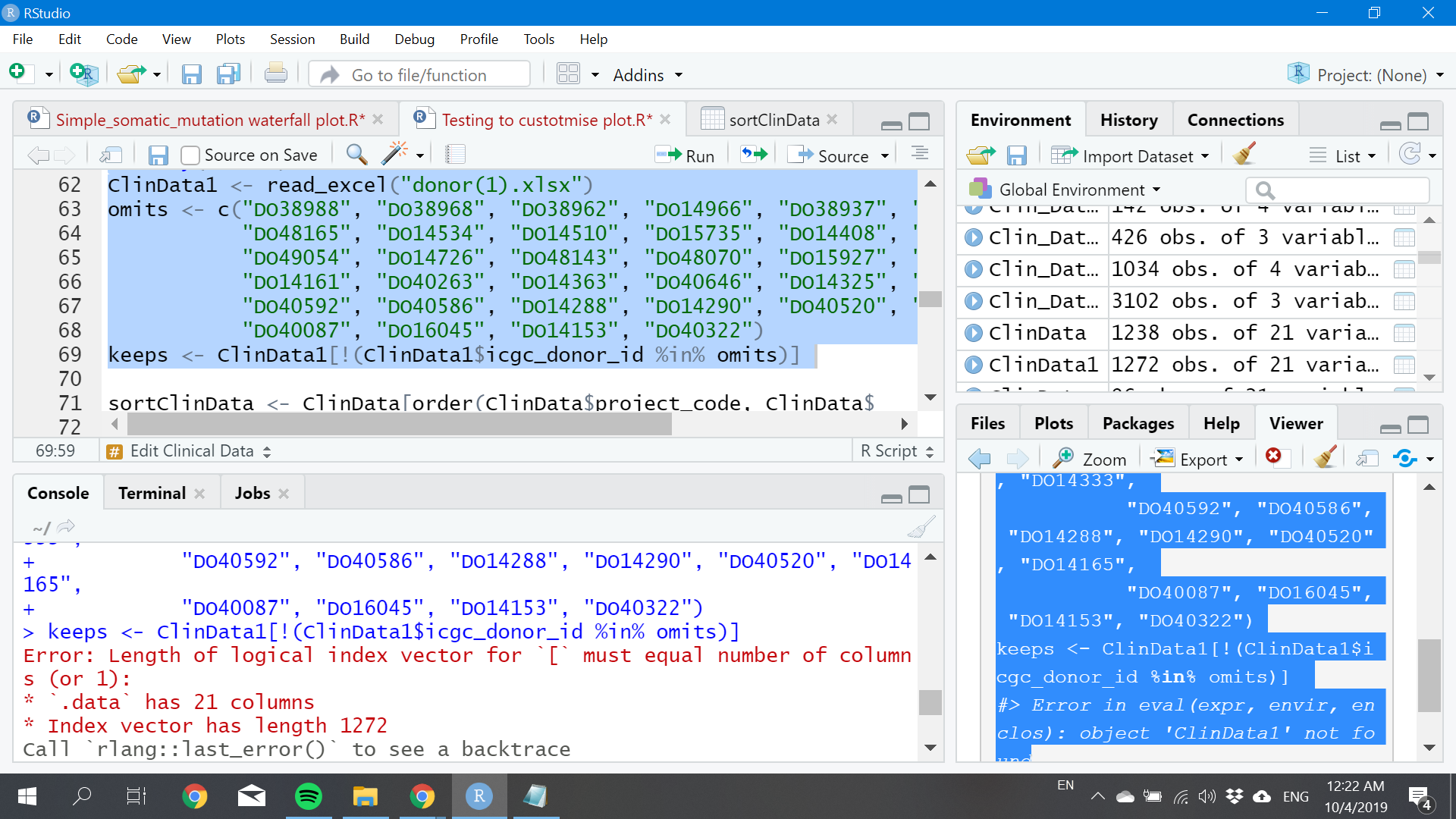
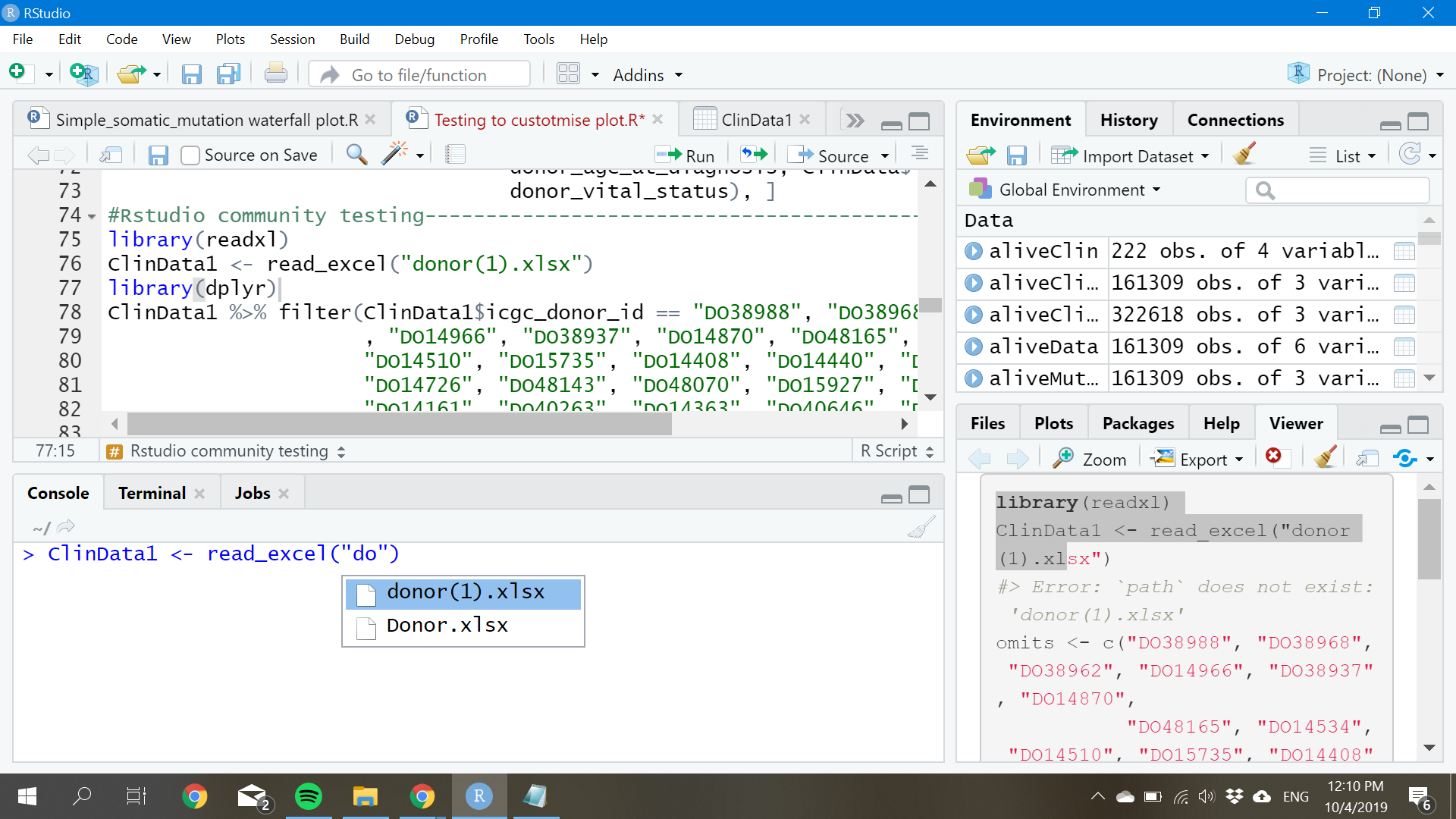
Hi would anyone point out the mistake in my coding? I am analysing data from International Cancer Genome Consortium and doing data cleaning. It is found that the mutation data doesn't match with the donor data, for which by more than 30 donors are missing out from the mutation data and I intend to clean up the particular donors. However, when i am trying out various ways to subset the data, error of object not exists even though when I checked it it is physically present in my data frame.
library(readxl)
ClinData <- read_excel("Donor.xlsx")
ClinData %>% filter(ClinData$icgc_donor_id == DO38988, DO38968, DO38962, DO14966, DO38937, DO14870, DO48165, DO14534, DO14510, DO15735,
DO14408, DO14440, DO49054, DO14726, DO48143, DO48070, DO15927,
DO14152, DO14161, DO40263, DO14363, DO40646, DO14325, DO14333,
DO40592,DO40586, DO14288, DO14290, DO40520, DO14165, DO40087,
DO16045, DO14153, DO40322)
For this, I did a lot of read up online but most of them are due to typo or unmatching case as R is case sensitive. As suggested, I did tried to check the variable in data frame by exists() but it showed up FALSE which makes me confused as it is clearly present in the data frame as shown in the picture below:
Welcome any comments or suggestion! Thank you in advance!