insure=read.csv(choose.files(),header = TRUE)
insure
View(insure)
dg=ggplot(data=insure,aes(x=age,y=charges,color=region))+geom_point()+geom_smooth()
dg
set.seed(12345)
insure2=subset(insure,select = -c(region))
View(insure2)
partss=createDataPartition(insure2$smoker,p=0.75,list=F)
partss
train7=insure2[partss,]
train7
test7=insure2[-partss,]
test7
na.omit(insure2)
is.na(insure2)
dim(train7)
table(insure2)
dim(test7)
modelfit7=train(as.factor(smoker)~.,data=train7,method="glm")
modelfit7
prediction7=predict(modelfit7,data=test7)
prediction7
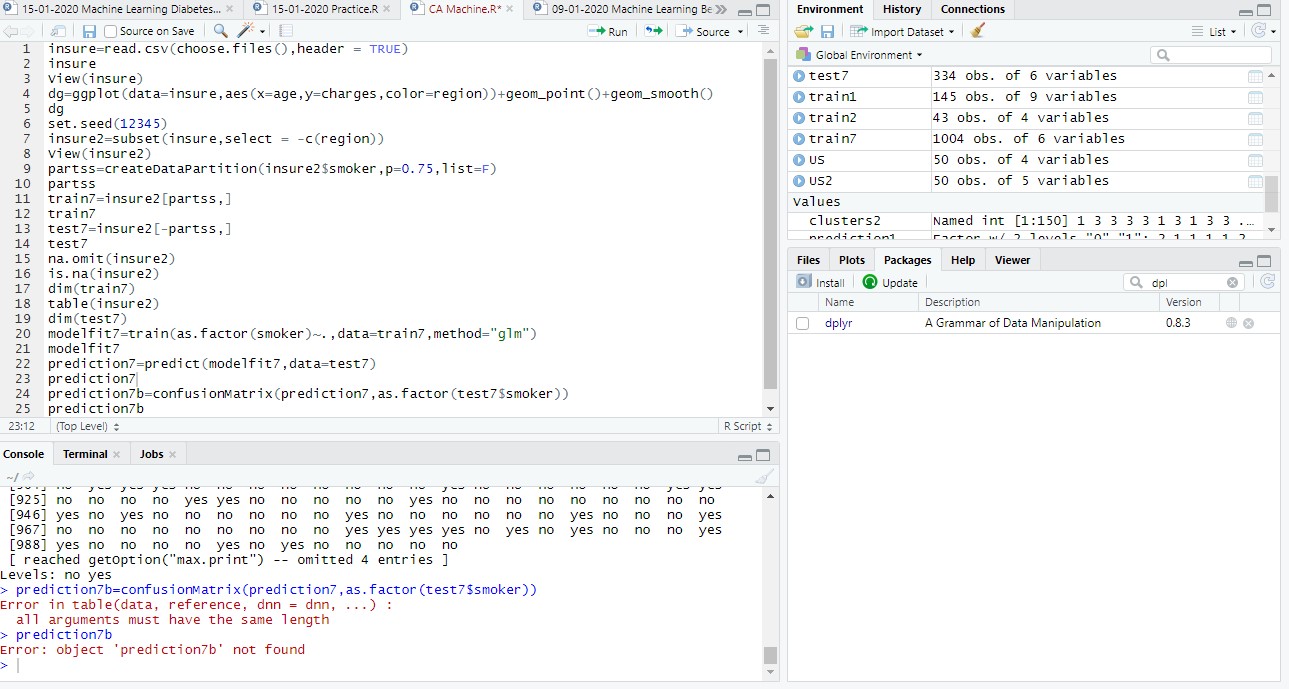
prediction7b=confusionMatrix(prediction7,as.factor(test7$smoker))
prediction7b
Hi, and welcome!
I'm sure that you have heard of lazy evaluation in R. The same principle applies in the community here, which is why a reproducible example, called a reprex is important. The question will attract more and better answers.
Hi, Thanks for the reply
I am a beginner and dont know much about R. I am getting the mentioned error. Any visible mistake that i did in the coding??
1 Like
There may be, but it's too difficult to peer at what we're working with, which is why a reprex is so helpful.
The error message comes from this line of code, apparently prediction7 and test7 don't have the same number of rows, possibly because there are NAs in test 7 but we can't be sure with out a proper REPRoducible EXample (reprex).
This topic was automatically closed 21 days after the last reply. New replies are no longer allowed.