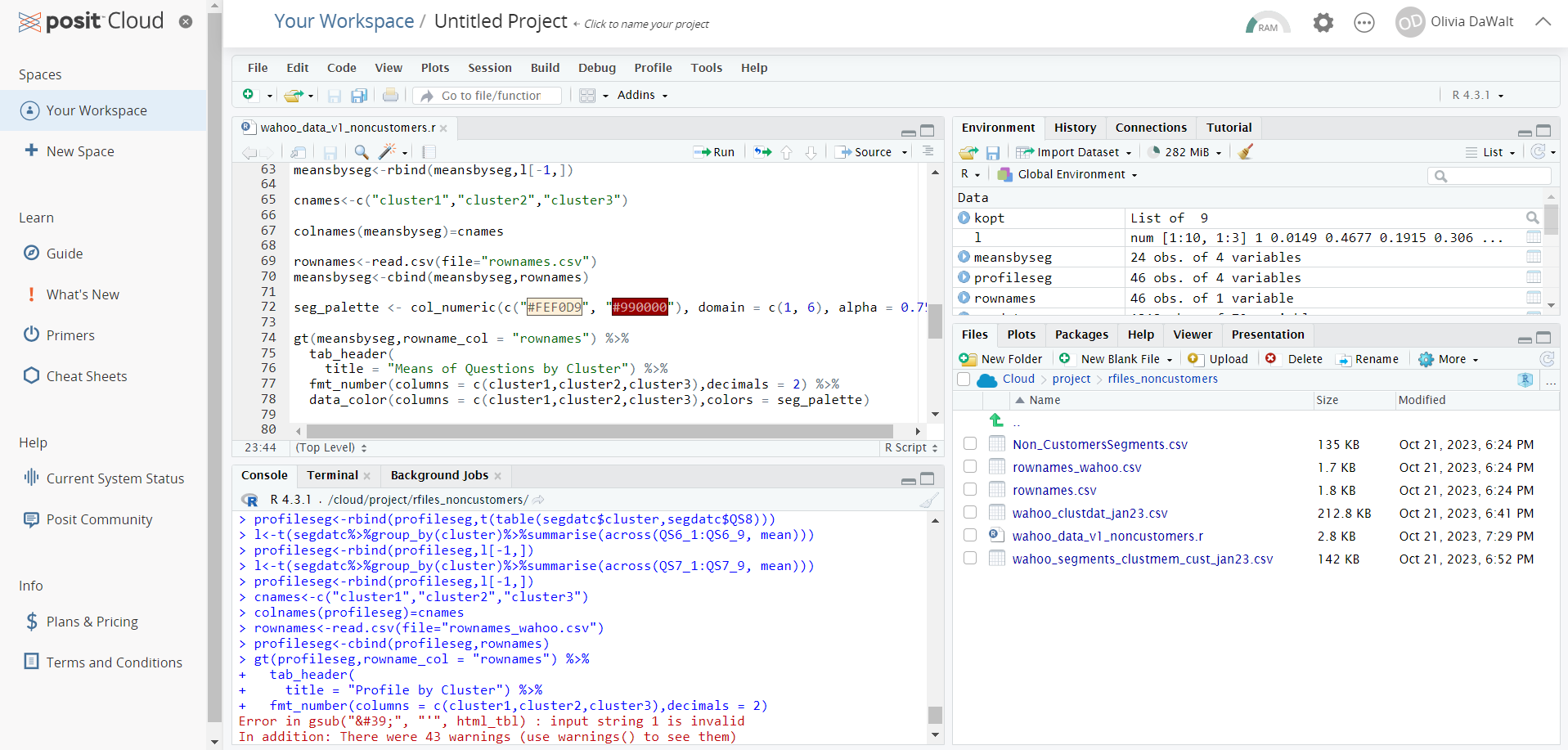
Below is the code and I've attached a screenshot as well for the output, I'm receiving.
segdat<-read.csv(file="wahoo_clustdat_jan23.csv")
segdatc1<-segdat%>%filter(Q109_1=="Sample")
set.seed(123)
segment_dat<-segdatc1[,57:79]
segment_dat$mean=rowMeans(segment_dat)
segment_mcdat<-data.matrix(segment_dat[,1:23]-segment_dat$mean)
gdist<-get_dist(segment_mcdat,method = "manhattan")
wss <- function(k) {
km<-kmeans(gdist, k, nstart = 30, iter.max=500)
km$tot.withinss/km$betweenss
}
k.values <- 2:8
wss_values <- map_dbl(k.values, wss)
plot(k.values, wss_values,
type="b", pch = 19, frame = FALSE,
xlab="Number of clusters K",
ylab="Total within-between clusters variance")
kopt<-kmeans(gdist,centers=3,nstart=25)
cluster<-kopt$cluster
segdatc=cbind(segdatc1,cluster)
write.csv(segdatc,file="wahoo_segments_clustmem_cust_jan23.csv")
meansbyseg<-table(segdatc$cluster)
l<-t(segdatc%>%group_by(cluster)%>%summarise(across(Q1_1:Q2_12, mean)))
meansbyseg<-rbind(meansbyseg,l[-1,])
cnames<-c("cluster1","cluster2","cluster3")
colnames(meansbyseg)=cnames
rownames<-read.csv(file="rownames.csv")
meansbyseg<-cbind(meansbyseg,rownames)
seg_palette <- col_numeric(c("#FEF0D9", "#990000"), domain = c(1, 6), alpha = 0.75)
gt(meansbyseg,rowname_col = "rownames") %>%
tab_header(
title = "Means of Questions by Cluster") %>%
fmt_number(columns = c(cluster1,cluster2,cluster3),decimals = 2) %>%
data_color(columns = c(cluster1,cluster2,cluster3),colors = seg_palette)