Hi all,
I'm working on a project that involves forecasters who forecast the sales of a firm one or more times during some fiscal period (say, year or quarter). However, it's economically meaningful to consider which direction they are forecasting relative to the prevailing mean or median of the forecast(s) issued before the current observation (the "consensus"). The problem is that there are several "lookback" type conditions that make the logic tricky to implement in a succinct manner.
Specifically, the following conditions must apply:
-
The previous forecasts that form the consensus must be for the same firm-time period (so, Apple's Q1 2021 forecasts are the only ones forming the consensus against which another Apple Q1 2021 sales forecast might be measured).
-
The analyst never considers their own forecasts when forming their perceived consensus (so if the same analyst forecasts 6 times in a row, but no one else does, there is no consensus at any point).
-
It is not reasonable to assume that every analyst becomes aware of every other analyst's forecast and can do anything with them immediately. So, the analyst only considers forecasts that are at least 3 days old (or older) when forming their consensus. So, if someone else forecasts on the same day, the day before, or 2 days before, those values should be ignored.
-
The analyst only considers the most recent forecast from each analyst (so if analyst 1 forecasts twice, then analyst 2 forecasts later, analyst 2 only treats the most recent forecast from analyst 1 as the prevailing consensus).
To get a sense of how this works, I dummied up an example that I hope captures all of the possible quirks.
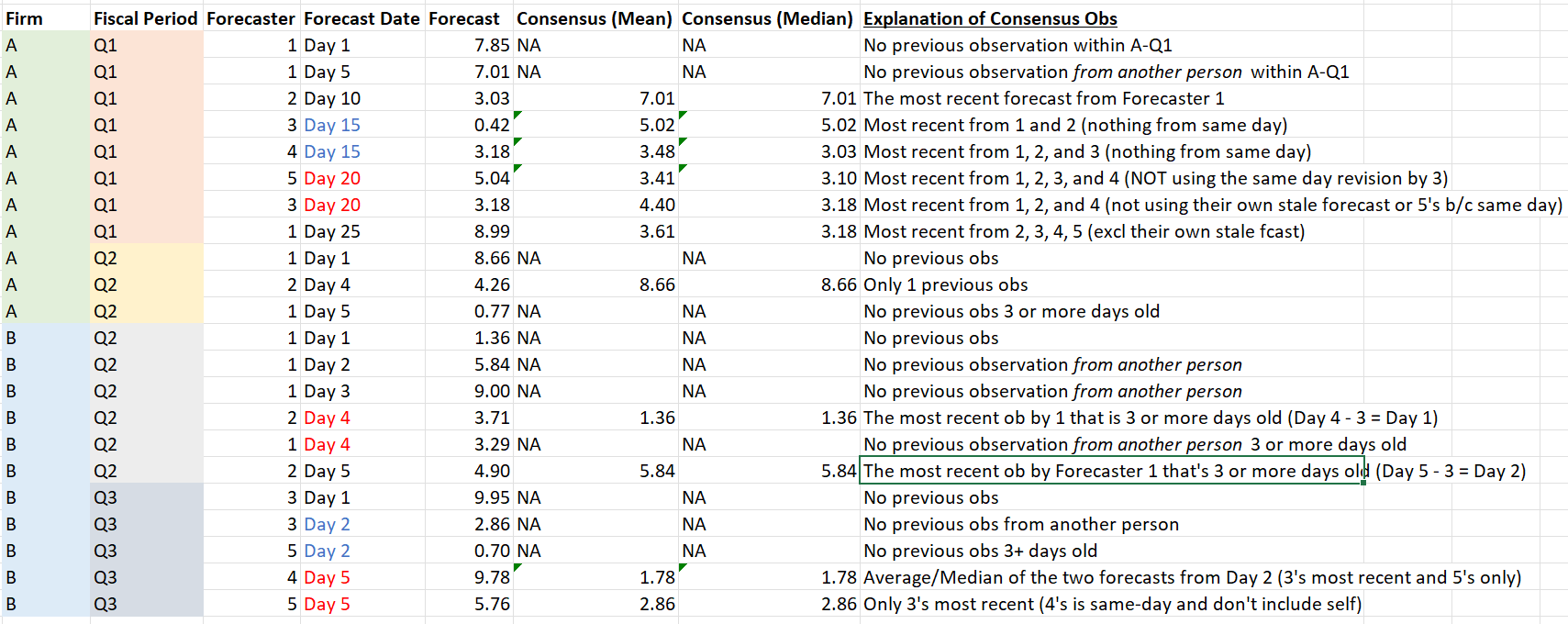
To help with the subsets, I've highlighted a few relevant breakpoints (different firm-fiscal periods, days where multiple forecasts are issued) and explained how each consensus here was constructed.
So far, I've made the following attempt, but it lacks a few of the features I'd like (namely the median, but also the 3 day lag rule, although that's much simpler to add).
#dat = the data shown in the image, held in a data table structure (not necessary, but what I'm most familiar with)
dat <- dat[order(firm, fiscal_period, forecast, forecast_date)]
#Numbers the duplicate analyst forecasts per firm-fiscal_period(so, forecast revisions)
dat[, occ := 1:.N, by = .(firm, fiscal_period, forecaster)]
#Determines the number of forecasts outstanding as of a given forecast
dat[, n := cumsum(!duplicated(forecaster)), by = .(firm, fiscal_period)]
#Creates value1, which will be used to calculate the consensus, preserving forecast value so it isn't altered
dat[, value1 := value, by= .(firm)]
#Pulls previous value and differences, if applicable, or zero
dat[, x := c(0, diff(value)), by = .(ticker, fiscal_period, forecaster)]
#If multiple forecasts per analyst, replace value1 with the differenced value
dat[occ>1, value1 := x,]
#Calculate the consensus by forecast period.
#This whole thing works by effectively removing the prior forecast value from the current forecast value, leaving only the current value in the consensus.
dat[, cummean := cumsum(value1)/n, by = .(firm, fiscal_period)]
I appreciate any help that you all can offer!