I'm trying to automate combining two csv files containing twitter data from the twitteR package. Historically I have been combining manually in Excel. I have imported both files into R then exported to csv to get formats the same, however I suspect there is something going on with the id field. The combined tibble has duplicates, which I fully expect due to overlap of dates, but I can only filter out a handful, most of them remain.
files <- dir(data_path, pattern = "*.csv") # get file names
u308df <- files %>%
# read in all files, appending the path before the filename. Source:
# https://serialmentor.com/blog/2016/6/13/reading-and-combining-many-tidy-data-files-in-R
map_df(~ read_csv(file.path(data_path, .)))
When I use read.csv as opposed to read_csv I get the below warning 15 times:
"In bind_rows_(x, .id) : Unequal factor levels: coercing to character"
I suspect it has something to do with handling the bigger historical data set in Excel and it is somehow different to the recently imported data.
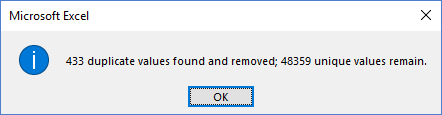
If I export the combined tibble to csv and then in Excel, go to Data, Remove Duplicates, Excel has no issues finding the duplicates.
There are couple of things going on that have little to do with each other, so I'll try to go over them:
By default, read.csv (so, base R version) will use stringsAsFactors as set on your machine. If you didn't do anything with it, it'll be TRUE and read.csv will read all strings and convert them to factors. When you read data from multiple files, it'll read first file and create data frame with factors in, e.g., ID column. When it reads the second file, presumably, your ID's will be different and that is why you are getting a warning about converting factors to strings.
readr::read_csv doesn't convert anything to factors, unless you explicitly tell it to do that. Therefore, you are not getting the warnings when reading data in.
First two points, however, have nothing to do with duplicates. Neither approaches will remove duplicates, so I'm not sure why you have this expectation. If you do want to remove duplicates, take a look at dplyr::distinct() function that does just that.
Sorry I probably didn't explain myself clearly. When I run the below on the combined tibble:
# Filter out duplicated id variable
u308df <- u308df %>%
distinct(id, .keep_all = TRUE)
Only a handful of duplicates are removed (70 or 35 pairs). If I then export to Excel I can remove another ~433. I'm unable to determine why R can only detect some duplicates in the id field? Have you come across this issue before? read_csv parses the id field as id = col_double(), I have tried changing after to chr but it didn't help.
I don’t have a direct answer to your question but I find the janitor package really useful here. It has a get_dupes() function that you can use to explore duplicate observations in your data. This function is documented on the package’s README.md file.
I suspect that you have some variables containing data that Excel and R treat differently. This is just a hunch, but perhaps there are dates or double values that could be the source of this? Something to keep an eye out for as you check your data.
He is passing an optional variable argument (id) into distinct(), so I think that the other variables are not considered. So it is with the id variable that there is something going on. The first error message also hints into some problem with id.
What I suspect is that the variable id got coerced to factors upon import by some base R function (such as read.csv()) and what you are comparing are not the actual id values but the factor levels. Converting your factors to characters before running distinct() might do the trick.
The OP is using read_csv() though... and the factor error message is when he tries with read.csv() instead. So maybe it is something else going on with id.
@chalg, if you give us some info on your data, it will be easier to try to understand what is going on.
Oh this makes perfect sense @prosoitos. I had read that part earlier but it slipped my mind. Sorry to confuse things @chalg! Keep the janitor package in your back pocket for next time.
Hmmm... read_csv() allows you to define column types. One way to fiddle around with this could be to force id to be imported as a character vector. The col_types argument is what you’d want to modify here.
Ok thanks for all your help. I will try the col_types argument tonight after work to import as a character vector. Note: "In bind_rows_(x, .id) : Unequal factor levels: coercing to character" was a warning in read.csv, not an error.
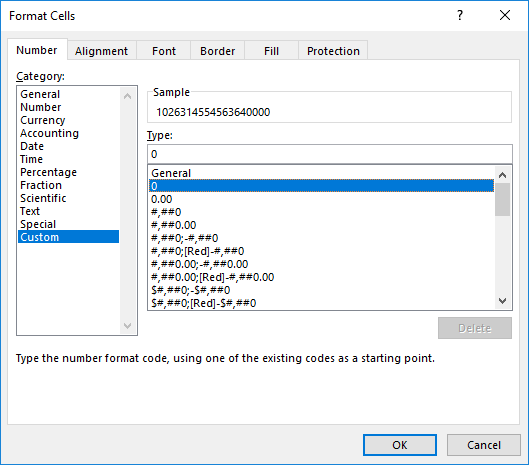
Is there a way of stopping Excel from changing the id column? For example from 1026314554563640000 to 1026310000000000000. This is the problem that I try and get around by formatting the id column in Excel before saving as .csv format (prior to import into R), which causes additional problems when trying to combine data with purrr functions.
I store in .xlsx format because you can only collect 7 days of twitter data at a time and I have around 3 months worth in the .xlsx.
The current workaround is to just append new data to the historical in one file via Excel, format the id column then save as a .csv and import into R.
Alternatively, If I create two .csv files and perform the same formatting on the id field as per above on both, then R is able to detect the same duplicates as Excel after importing both files with a purrr function. However this involves manual workflow, which I was trying to avoid.
It seems that when you open a csv and save, Excel mangles the ID column. The reason I use Excel is to store the historical data in .xlsx format, which leaves the id alone, i.e. you can open and save with no issues.
On the off chance this isn't clear... just because Excel "claims" CSV files (by putting its icon on them and setting itself as the default application that opens when you double-click one) doesn't mean a CSV is in any way dependent on Excel. It's just a plain text file with a certain agreed-upon layout. You can open it up in any plain text editor, or even directly in RStudio. A CSV isn't particularly nice to read on its own, but it's not a good idea to go tweaking it by hand anyway.
So if you want to keep your ID values from getting mangled, you don't need to work with xlsx files (though of course you might choose to do so for other reasons) — you can just cut Excel out of your workflow completely as @mishabalyasin suggested.