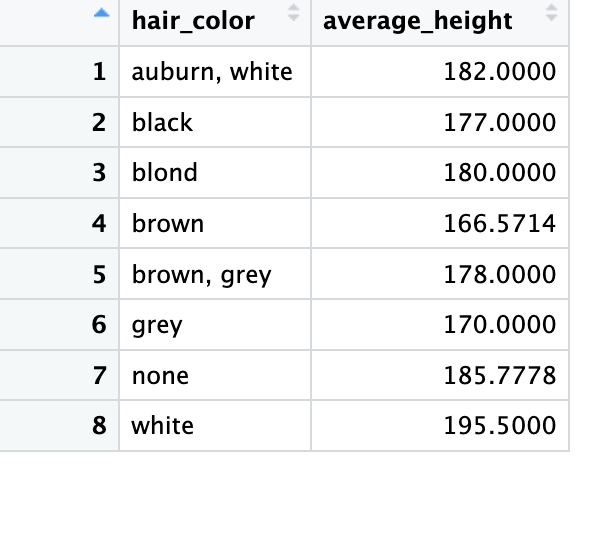
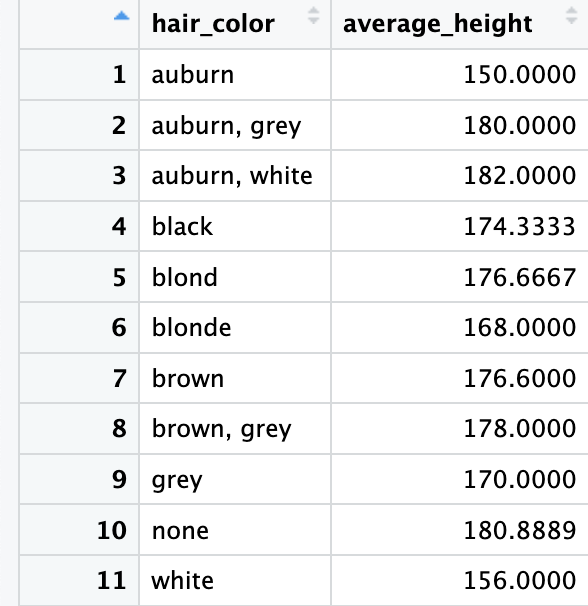
Hey everyone, beginner to R. I have two pieces of code below, which I created from the starwars dataset, which resulted in different mean values for the heights ("blond" hair, for example, has a clearly different average height in both results). Can someone explain why? Thank you.
1st Piece of Code:
In this piece of code, since the pipe operator takes the output of the expression on the left of the pipe operator and passes it as the first argument to the function on the right of the pipe operation, doesn't that mean that the drop_na() will get rid of all rows that contain NA? That means that after the drop_na() function, all NA values should be removed from the data set. Then, the hair colors will be grouped, and finding the average height shouldn't be an issue because all na values have been removed from the data set anyway.
2nd Piece of Code:
In this piece of code, I specify where I want the NA values to be removed, from all hair colors and heights. This means that all rows with an NA in their hair_color or height column will be removed. However, when I run this code, I get a different mean value for the "blond" hair than I did for the other piece of code above.
There are many more rows in the second data set. If you run stawars through drop_na() without specifying any columns, then an NA in any column eliminates the row. By specifying columns in the second version, the NA values in other columns remain in the data set.
So which result would be the correct one in terms of the mean height ? If all rows with NA in their column are removed in the first result (including the hair_color and height column), why didn't that give me the same mean heights if all NA's were removed from the hair_color and height column when specified in the second result?
Which case is correct depends on what you want. If you want the mean only from rows where all the columns have values, then use drop_na(). If you want the mean from rows where neither hair_color nor height are NA, but other columns may have NA, use drop_na(hair_color, height).
Here is a small example. Using drop_na(), the first row is dropped because column A has NA though Hair and height have values. Using drop_na(Hair, height) keeps that first row in the data set.
library(tidyverse)
DF <- data.frame(A = c(NA,1,2,3,4,5,6),
Hair = c("Black","White",NA,"White","Black", "White","Black"),
height = c(1,2,3,NA,5,6,7))
DF
#> A Hair height
#> 1 NA Black 1
#> 2 1 White 2
#> 3 2 <NA> 3
#> 4 3 White NA
#> 5 4 Black 5
#> 6 5 White 6
#> 7 6 Black 7
DF |> drop_na()
#> A Hair height
#> 1 1 White 2
#> 2 4 Black 5
#> 3 5 White 6
#> 4 6 Black 7
DF |> drop_na(Hair, height)
#> A Hair height
#> 1 NA Black 1
#> 2 1 White 2
#> 3 4 Black 5
#> 4 5 White 6
#> 5 6 Black 7