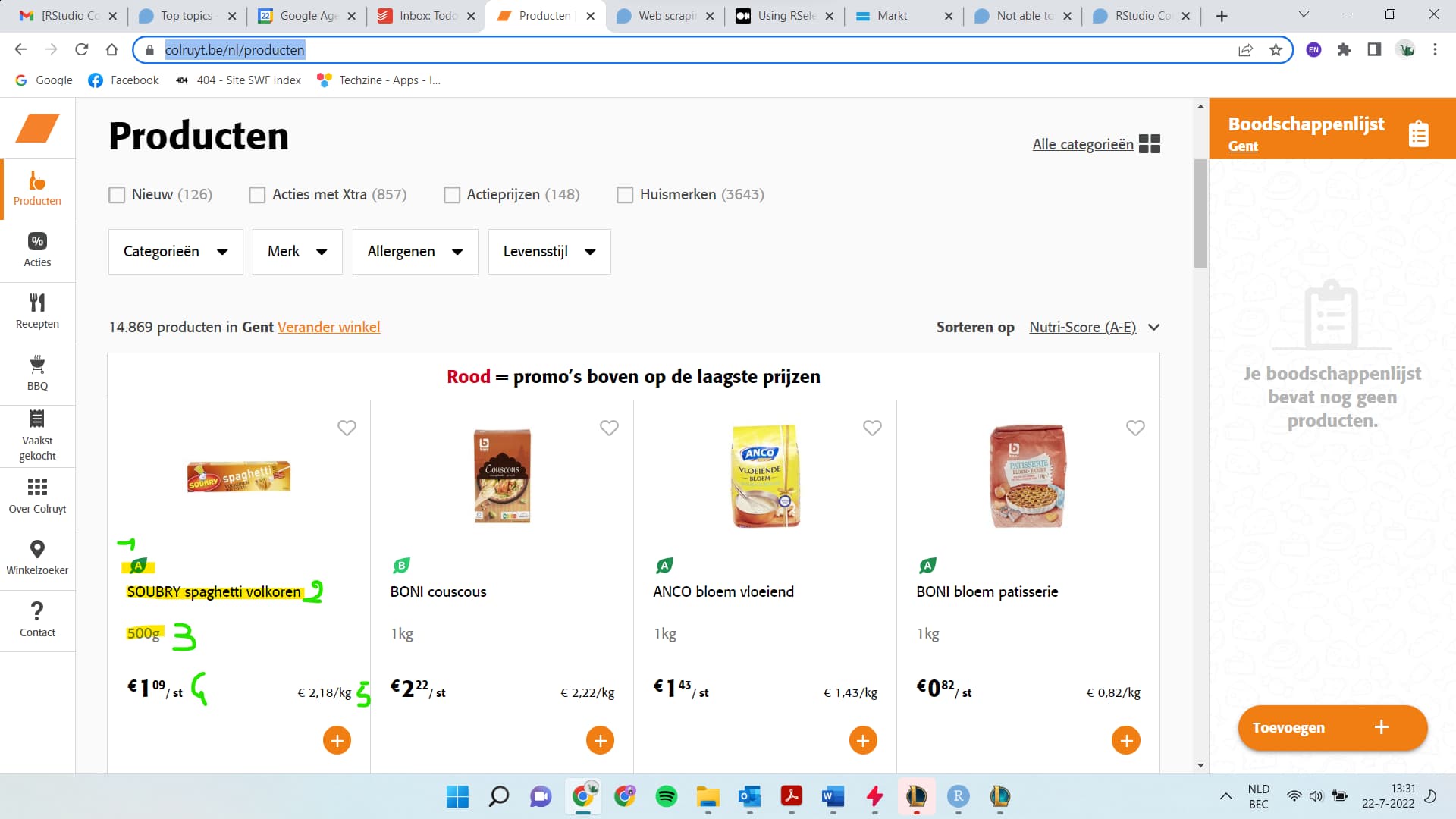
For my masters thesis I have to collect data from a website, all data is publically available, but doing it by hand is very time consuming.
I want to scrape the following website: https://www.colruyt.be/nl/producten
More specifically i want to scrape the name of the product, the price, weight, price per weight and the name of the little leaf label ( it has category A,B,C,D,E).
What have you tried so far? what is your specific problem?, we are more inclined towards helping you with specific coding problems rather than doing your work for you.
Could you please turn this into a self-contained REPRoducible EXample (reprex)? A reprex makes it much easier for others to understand your issue and figure out how to help.
If you've never heard of a reprex before, you might want to start by reading this FAQ:
#what i have tried so far is this, i want to get the title for example of the products over the page:
library(rvest)
productname <- read_html("https://www.colruyt.be/nl/producten") %>%
+ html_nodes(".card__text") %>%
+ html_text()
productname
(0)
but i don't get any output, so i am doing something wrong, but idk how