So I am designing a biological experiment by which i need to distribute 587 different peptides between 80 buckets. Each peptide should be present in 4 buckets, and the restriction is that if peptide X is present in a bucket, then peptides X-2, X-1, X+1, and X+2 are not allowed in that bucket.
I tried to brute force my way through this, by just randomly sampling different combination of buckets until i found a combination that fit this. HOWEVER, i quickly realized I am looking for a quite rare event, because I ended up the same peptide picked twice for at least one pool (and most often in many pools).
This is the code I tried: (not suggesting this is the way forward, but just to share with you what I tried)
# Set rules
buckets = 80
size = 30
coverage = 4
iterations = 100
system.time({
# Create [iteration] random pools
pool_assignent = list()
for (i in 1:iterations) {
pool_assignent[[i]] <- data.frame(pool = rep(1:buckets, 30), peptide = sample(rep(1:587,4), replace = F)) %>%
split(.$pool) %>%
map(~ .$peptide)
}
# Name the pools
names(pool_assignent) <- paste("i_", 1:iterations, sep="")
# Find minimum within each pool
min <- pool_assignent %>%
map(map, dist) %>%
map(map, as.vector) %>%
map(~ bind_rows(.)) %>%
map(~ min(.)) %>%
do.call(rbind, .)
print(min(min))
})
Please let me know if you have any ideas. I did have a look at Sampling without replacement multiple times and ensuring equal samples but was not able to use this code in an effective way. I do believe however, this has to be a structured selection process, and not a random sampling.
I'm behind @jmcvw again. My sketch doesn't rely on randomization, since that's not necessary—the assignments can be arbitrary, provided they follow the rule.
I would first make buckets and split them into the four sub-buckets required for each peptide.
For each element in the peptides vector, assign to the next available element of the current sub_bucket. Then recycle: the next recycling of sub_buckets is necessarily far enough away from the last element of sub_bucket.
This depends, of course, on peptides being ordinal.
Thank you both for responding and for working on this for me. I appreciate it a lot!
To the problem:
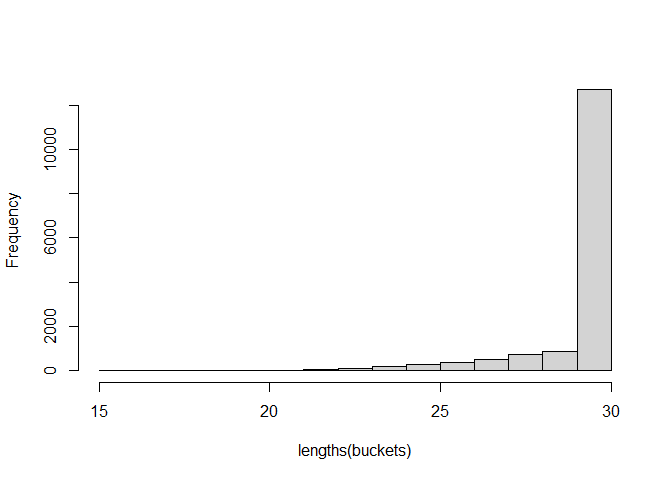
I ran jmcvw's first suggestion that rely on random sampling overnight (1,000,000 iterations) and found buckets with a range of 27-30 peptides in each bucket.
Then I ran jmcvw's second suggestion that did not require randomization, which is obviously both faster and gives more equally filled buckets.
However, this is the thing I should have mentioned earlier....SORRY! One my requirements is that the buckets should be as different as possible. With the approach that does not rely on randomization, the buckets repeat themselves and there is only 20 unique buckets:
Do you think there is a way to build unique buckets, while still following the rules below, without incorporating randomization? I understand it makes it more complex, but please let me know what you think.
For the randomizaed buckets, there is no issues with identical buckets (by chance?):
I probably should have suggested a longer, rather than shorter, object to hold the four-bucket pieces. With 588 peptides, including the final two dummies to round the number required, it would be just
buckets <- paste0("B",seq(1:80),"")
sub_buckets <- split(buckets, ceiling(seq_along(buckets)/4))
pool <- rep(sub_buckets,147)
Each peptide draws a sub-bucket from the pool; there are twenty unique sub-buckets so, peptides should be consistently 20 sub-buckets apart, meeting the requirement for no near-neighbors in the same bucket. Because the buckets can be created in the same way as peptides above, although not assigned once created, no sub-bucket set is privileged over another. And regenerating the bucket list can be done to test for distribution. I'd expect that one of the tests for normality could be drafted as the metric.
Creating the object from two equal-length vectors shouldn't be difficult at all.
Thank you, I will try to work this out. I appreciate it!
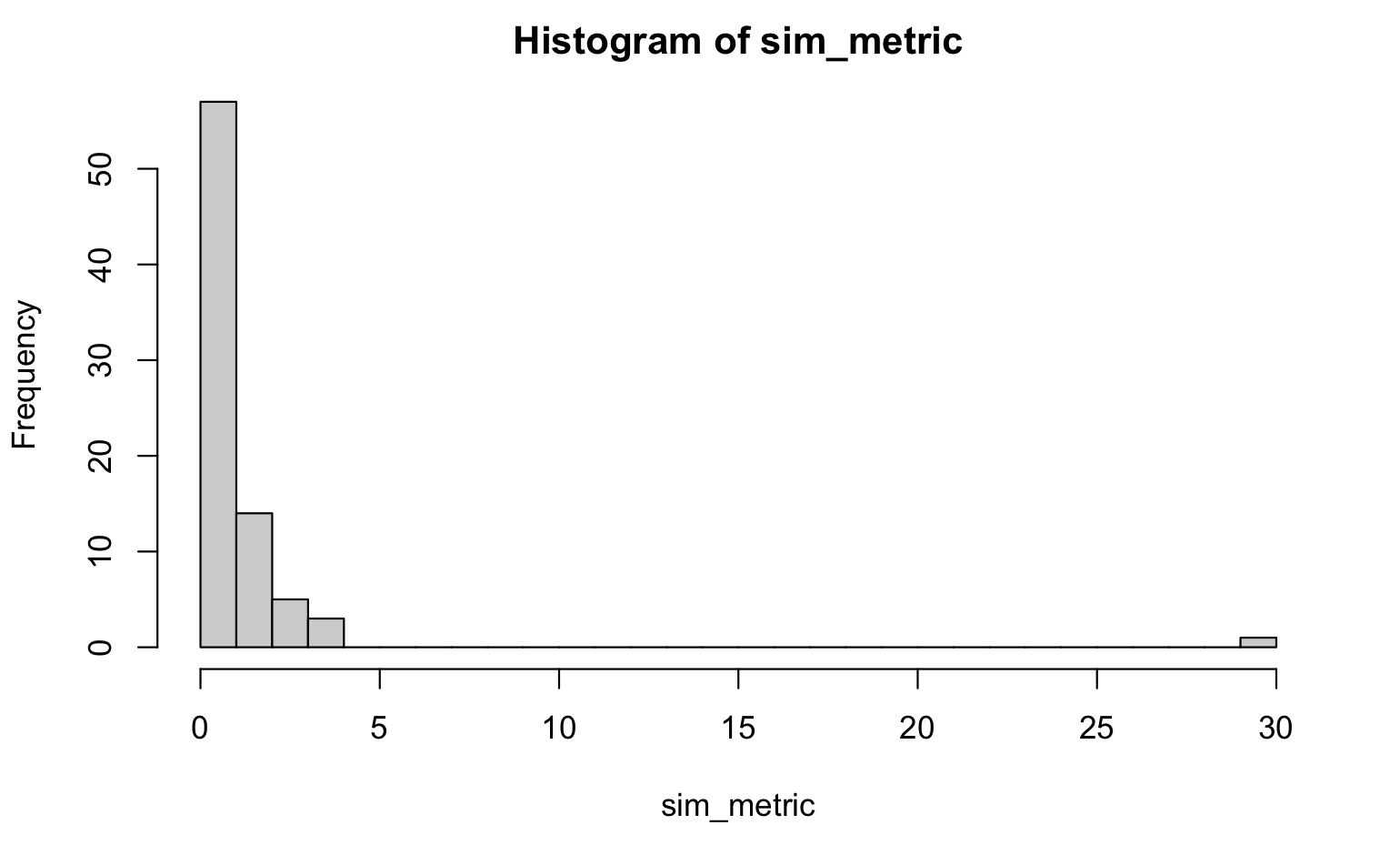
Meanwhile, i worked on the "randomization" code example by jmcvw and calculated the intersect between each bucket. Actually, it looks pretty good, the buckets do not share much:
# Determine "uniquness" of buckets
sim_metric_list = list()
for (i in 1:80) {
for (j in 1:80) {
sim_metric_vector = vector()
intersecting_peptides <- intersect(x = selected_bucket[[i]], y = selected_bucket[[j]]) %>% length() + 0
sim_metric_vector[j] <- intersecting_peptides
}
sim_metric_list[[i]] <- sim_metric_vector
}
sim_metric <- do.call(rbind, sim_metric_list)
hist(sim_metric, 30)
Seems almost unlikely to get something so good, but I also have not gone into understanding the code (busy day, my only lab member resigned today...). Any thoughts?
Looks like a power distribution, which is plausible. Proximal ordinal peptides land by design in non-overlapping groups of 4 buckets. Maximizing Euclidean distance might be another approach.
I work in academia, and this will be helpful for a research project I am working on. Can I ask if you are willing to send your names to me via Direct Message so that I can acknowledge you properly for the help in any upcoming publication that uses this code?