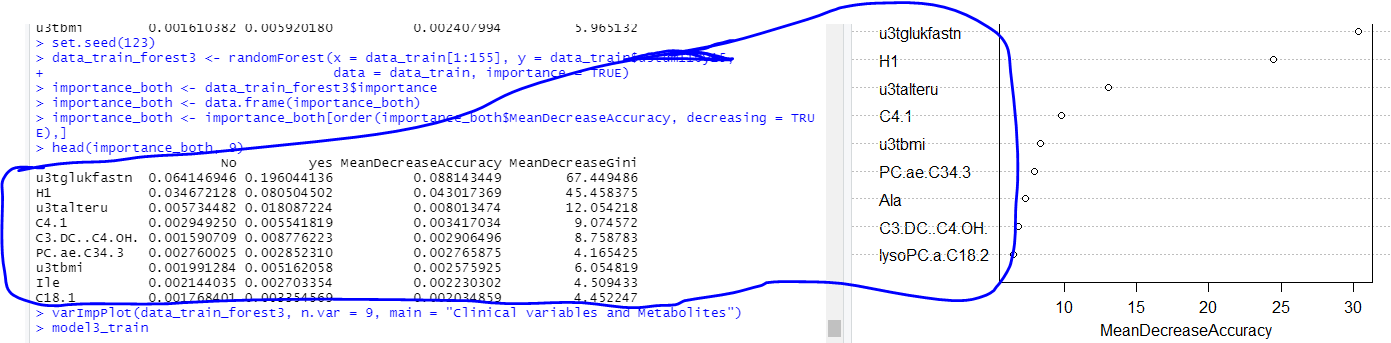
R code:
set.seed(123)
data_train_forest3 <- randomForest(x = data_train[1:150], y = data_train$T2D,
data = data_train, importance = TRUE)
importance_both <- data_train_forest3$importance
importance_both <- data.frame(importance_both)
importance_both <- importance_both[order(importance_both$MeanDecreaseAccuracy, decreasing = TRUE),]
head(importance_both, 9)
varImpPlot(data_train_forest3, n.var = 9, main = "Clinical variables and Metabolites")
I used the above code to select the top 9 varibles and found the variables from "head(importance_both, 9)" and varImpPlot are a little bit different? (Sorry if it is stupid query, I am just a beginner on R)
by the way, I used the cross validation "rfcv()" to know when we including 9 variables we can get the optimal model, so when we choose these 9 variables should we we do another cross validation or kind of replication ? as we know each time we run randomforest, we can get different order of importance variables?
It will be much appreciated if someone could help anwer it ![]()