I came across this quote advising when to use a database:
If your data fits in memory there is no advantage to putting it in a database: it will only be slower and more frustrating
I have nothing but profound respect for Hadley and without his contribution R wouldn't be half a great to use at it is - but here I think he's flat out wrong. Unfortunately, he isn't the only one.
I agree that this can be true for small datasets in which a database would have scanned the whole set anyway. But let's suppose that I happen to have 64 gb of RAM in which I load a 32 gb of data in memory. Now I want to apply a filter. My R code, using dplyr or not, is going to have to scan the entire dataset, row by row, and return a huge subset to me. Worse still, if I have 2 datasets each with 10 million rows and I decide to perform a join .. the row by row scanning to satisfy the join is going to be brutally slow.
On the other hand, database vendors have spent decades perfecting their engines to take maximize data retrieval efficiency with sophisticated query engines and indexes. The R code can submit a query to the database engine and retrieve only the results. Those results would have come back 1000's of times faster because the database engine has indexes that support things like the above-mentioned filter and joins.
The idea that something is always faster because it's in memory is simply not true. Saying this is bound to lead R coders in a wrong direction.
I agree with your arguments, but I think your main assumption is where the difference is. 64 GB of RAM is by no means a usual case. If you have tens of GB of data then for sure you should be using a DB.
The comment (the way I understand it) is more about the case where you have something like 10k-100k rows. Putting that into DB will most likely be slower and more frustrating, as stated.
What you are describing qualifies for "data not fitting into memory" (especially regarding joins and other "memory-expensive" operations. Having said that, you probably want to prototype your database pipelines using in-memory samples, anyways. It makes all sense to use the efficiency/scale of database server to compute on data in "production". However, designing sophisticated dbplyr solution for dataset in SQLite is probably not proper use of time.
For workstations, I'm not too sure 64 gb is that unusual. I agree with you, but as it reads, if the data fits in memory- so let's say I have only 16gb or RAM (not too unusual) and I load 10 gb of data into RAM. It'll still be very, very slow if to decide to use R only.
I think to be accurate, if indeed Hadley meant this to be for small datasets, maybe he should qualify the statement that way.
I think there is more to databases than speed and ease of use (both of which are sort of debatable).
I am talking mainly about persistence of storage, multiple tables of normalized data with sophisticated joins and concurrent access by multiple users with varying level of access rights (select vs. update). These are areas where the databases really shine.
Also I can hardly think of a use case of a single tabular dataset of the size you describe (tens of gb) which would be generated outside of a RDBS environment (and thus be covered under Hadley's first bullet point "the data already is in database").
My experience with (Oracle) databases within my company is that they can be pathetically inefficient when indexes are not applied properly, so in-memory R would outperform the database every time, particularly using indexed joins via data.table, but also dplyr would be far quicker. This applies to data with 10s-100s millions rows and 10s GB.
A well-optimised database may well be better, but these are not always available and require knowledgeable DBAs. Also you can end up wasting a lot of time transferring data between the desktop and the database server.
See this for another opinion:
Conclusion
Lastly, I don’t deny there is a room for SQL even for data analysis. Especially when it doesn’t make sense to move all the data out of the database and you just need to answer very simple questions by using SQL queries to summarize the data. But, you need to have a clear strategy of when to use SQL and when to not use SQL. The best strategy I keep seeing with many R users is to fine tune the SQL queries to extract the data at a manageable size for your PC’s memory either by filtering, aggregating, or sampling, then import into R instance in memory so that you can quickly and iteratively explore and analyze the data with all the statistical horse powers.
I fully agree with you. Of course the database provides huge benefits outside of just performance.
But there are many big datasets in Kaggle for example that are quite large. The Taxi trips in NYC for 2016 comes in a 16 gb data file. If I were to follow Hadley's advice, I should load that whole dataset in memory since it's smaller than my available memory (64 gb in my case). He claims that it will be faster that way. However, I would argue that it should be loaded into a database first to gain the benefits of persistence across sessions and to enjoy faster (much, much faster) data manipulation using the database engine.
Performance is an engineering problem, and engineering problems rarely have a single solution (that is for mathematicians and their abstract concepts). You can put the data into a database and learn SQL (which a data person should know anyhow), or you can throw some hardware on it and solve it by brute force, easily done in the age of cloud computing when resources are rented by the hour.
In fact if performance was what you were after you would not be doing it via dplyr at all, but via data.table.
The thing is that playing with Kaggle datasets is far from real world scenarios. In a real world the 16 gb file would be spread over a number of tables in a relational database, because that is how the world works.
But it would be there not for performance reasons, but because:
it would be used by a team of users, requiring a single version of "truth"
it would be too valuable to give out with write access to a bunch of analysts (select is enough)
it would require centralized access management and logging of usage
it would require a centralized and controlled backup
And in addition to these there would be performance benefits. Especially so if the database was designed and administered by an architect / DBA who knew his stuff and set up his indexes well; these really do make a difference.
I suppose that this is what Hadley had in mind when he wrote that a dataset is either small, or in database already.
If you hear his talks he recommend dplyr to files around a million rows. I totally believe what he meant by that statement was a normal file with around a GB or less of storage space. You took it too literally my friend.
This is the reason he created dbplyr. And yes your argument is valid but you aren't comparing Apple to apples.
In your case you should do it via database engine for sure .
I read your blog. I totally understand if your data is bigger than you should go for databases and that's the reason R community is trying to come up with integrated packages like
DBPLYR
MODELDB
DBPLOT
KEYRING ETC...
nobody is saying that you shouldn't use database. But say someone gives you a single excel file for analysis. For those cases you shouldn't do it in database.
But it was fun to read your article. Keep it up
arguments are tug wars of intellectuals --an Indian saying
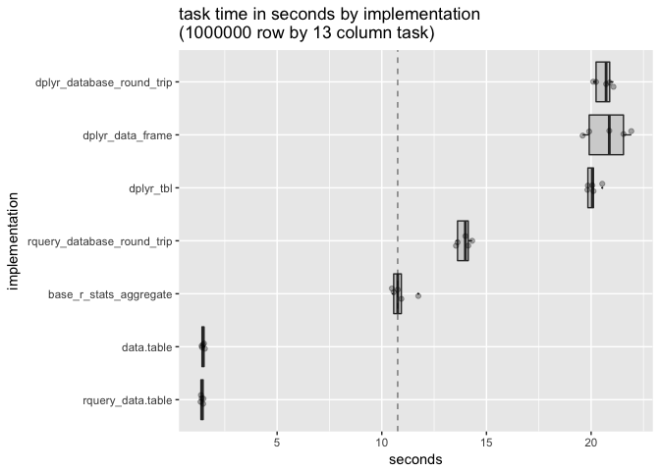
We have some performance examples where databases are quicker that dplyr in-memory, even after accounting for the round-trip time: rqdatatable: rquery Powered by data.table – Win Vector LLC . The database may be a better implementation, and may also have a higher degree of parallelism. That being said: I've yet to find a natural example that beats data.table (though some join exploiting pre-made indices probably can be designed to show such an effect).
You have really generated a sea of speculation from a single sentence in the dplyr docs (which are aimed at more introductory R users). For all your proposed use cases, yes, I agree with you, a database is better.
That said, I am very familiar with SQL, and I stand by my assertion that it can be frustrating. If you don’t ever find it to be so, that’s most likely because you’re suffering from the curse of expertise.
Thank you for your kind reply, Hadley. It's truly an honor. And I find your response highly reassuring. Of course, the memory vs database issue came up the minute the first in-memory dataset appeared. I remember having this same debate with C# developers in 2003 ..!
I do appreciate that your statement was meant for a narrower context than what it might literally sound like. You're also the man behind ggplot, the tidyverse, dplyr, testthat, roxygen, etc., and the author of the indispensable "Advanced R". I just worry that a certain percentage of the data science community will no doubt take those words as gospel because .. they come from you.
Thank you again for taking the time to read and reply to my message.
The internet has a way of being self-correcting when it comes to blind adherence to gospel… Also, I think we can give users at least a little bit of credit.
If you think we should add some sort of caveat to the docs, though, feel free to file an issue, and submit a PR. As @mishabalyasin mentioned, I think your 64gigs of local ram with tens of GBs of data is, in essence, not what that line is speaking to. However, obviously we want to be responsible (within limits!)
Thanks for that link from Emily's website. That's a great article - I enjoyed reading it; in fact, I bookmarked it. It's a great case of getting rid of preconceived notions long enough to objectively assess the best way to get a job done.
Fair enough about blind gospel. I actually would have been inclined to believe as you do, except for a few things. I see other posts in other blogs that also suggest to the world that databases are slower than memory operations. Also, even more distressing, is that during my research I came across a few posts where the poster would support this idea with a sentence that starts with "Hadley says .." - which is really where the word "gospel" came to mind. This can make it difficult for skilled technical people to get their technical advice heard if their less technical managers read these kinds of blogs given that most of them won't have enough technical understanding to read between the lines, so to speak. It also can be confusing to those who are new to data science.
64 gigs is alot for a laptop, sure. But I have 64 gigs on my desktop and it really didn't cost me that much money, so my guess is that even if it's not common now, it will be soon enough. Also, as the use of server-side products like R-Shiny, R-Connect, and Microsoft ML-Server are becoming more prevalent, the decision to use a database for performance and resource optimization becomes a real concern. I also know that I'd find the same thing with a 16gb file and had the same results - I did this with the NYC Taxi Driver database.
I have too much respect for Hadley to muster the temerity I would need to force his hand in correcting his documentation for a product he invented and produced. I'm perfectly happy to leave that decision up to him. But I will step up when I run across fellow data scientists who might be accidentally misled into thinking that relational databases are to be avoided.
In any case, I'm very encouraged by the willingness of the community here to politely consider and even give credence to different points of view. Thanks again for your response, Mara.
Open source thrives on users having such temerity — in fact, we call it contributing!
Seriously, though, correcting and helping with documentation is incredibly valuable. I don't know enough about this specific case to say what the best turn of phrase would be (it may be a matter of just saying for ~100,000 rows, or if beyond 𝒙 GB, you should consider moving to a database.
I would be the world's worst tidyverse dev advocate were I to let you leave this exchange thinking that not fixing mistakes in documentation was some sort of deference to expertise! It's not — we need contributors (such as yourself) in order to make software and documentation better (esp. given, as you pointed out, technological circumstances evolve). We (by which I mean everyone using and making packages) tend to have tunnel vision for our circumstances — I always work off of a laptop; I have 16GB of RAM, so I tend to mentally troubleshoot through that lens.
Anyway, long of the short: please contribute when you think something's wrong. Worst case scenario, you file an issue, and it gets closed. No harm no foul!