In a large data file, I want to identify duplicates based on several criteria. I use a small program for this, but it seems imperfect and does not detect input errors, for example. I would indeed keep finding a way to use something like the levensthein distance to detect errors like JEANINE/JANNINE. Only I can't find how to use this on the same column of sorting tables so that all the lines are compared with each other (first name for example). I thought about going through using python or sql in R but I'm not quite sure how to set this up. If you see how to do it or another method, I'm all ears! Thanks in advance
Yes of course, I juste have to download a more recent version of R, now it works, but the first name proposed don't look like mine. I tried to put in a variable prenomdiff all my distinct names thanks to a sql procedure and then use your method then but it don't works properly :
prenomdiff<-sqldf('select distinct(I_PRENOM) from data')
(somenames <- prenomdiff)
(targetnames <- prenomdiff)
test<-stringdistmatrix(a = targetnames,b=somenames,useNames = TRUE,method = "lv")
error message :
In stringdistmatrix(a = targetnames, b = somenames, useNames = TRUE, :
You are passing one or more arguments of type 'list' to
'stringdistmatrix'. These arguments will be converted with 'as.character'
which is likeley not to give what you want (did you mean to use 'seq_distmatrix'?).
This warning can be avoided by explicitly converting the argument(s).
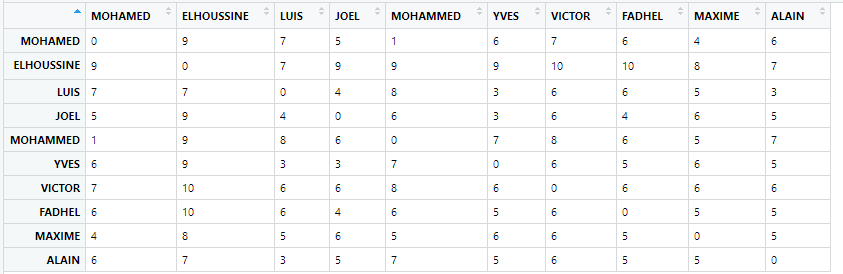
I test on a sample to show you what I want to got at the end. Moreover I would like to print only when the lv value is inferior or equal at 3, or color the values i want to put in evidence. I don't know if it's possible.
sqldf returns data.frames, whereas the stringdismatrix function wants to consume character vectors.
you can use R's $ syntax to selected a character vector column from a data.frame, for example
prenomdiff$I_PRENOM
Its possible to print and control the style of the matrix result.
For example :
I just tested stringdistmatrix on my laptop with inputs of 2000 by 2000, it resulted in a 32mb matrix and took less than 3 seconds.
when you say you cant apply the stringdistmatrix function on this size of data, what do you mean exactly ?
P.s. I'm surprised you aren't comparing a larger 'possibles' list to a shorter 'true' list. I have to wonder what it benefits you to compare a possible list with itself? but hope you have your own ideas about your purpose that it makes sense to you.
well, sorry I didn't look well, I do have an error but it's not link to the size, i tried with a df of more then 130000 and it's work.
With my df with 1900 rows I have this error that I don't understand :
Error:
! Column 1614 must be named.
Caused by error in `stop_vctrs()`:
! Names can't be empty.
x Empty name found at location 1614.
Run `rlang::last_error()` to see where the error occurred.
>
To answer to your PS, I am not sure either if what i'am doing is good, but my point is to find duplicates rows in a database so I think it's good like this.
My other problem now is to try to put an another variable from the initial data to compare if the names are close because of a mistake or by hasard (for example if date of birth are the same)
I don't know how to interpret your error... You didnt share any code in relation to it that might help me.
as we discussed previously stringdistmatrix does not take a dataframe as input.
Perhaps the process you are using to go from your data.frame to the stringdismatrix inputs is problematic, but I can't see it.
np2 represent a combination of name, first name and date of birth to try to identifie the person who are the nearest. The problem is that I have 30000 entries in my base and if I put more than 10000 in my sample, I have an error because it outstand the memory capacity of R. So this program is very good but don't take in charge enough lines in my case. I don't think there is any solution to resolve this.
you could try reducing the targetnames to only those beginning with a particular letter of the alphabet.
this should result in an object roughly 26th the size of the total otherwise.
you can iterate the analysis over each targetname set beginning with a new alphabetic character
at each stage keep what is interesting and discard what is not. recombine at the end.
I see what you mean, but I have no idea of how put this in place
Also, I have of course each output two time, in each way :
(jean dupont / jean dupond and jean dupond/ jean dupont)
I'm sure I can do something to correct that but I don't find out for now.
This is very great! It give exactly what I need! Also, do you know how to deal with my problem of repetition in each way
(002 jean dupont/ 043 jean dupond and 043 jean dupond/ 002 jean dupont) (tell me if my explication is not clear)?
It can be good because it will delete the half of the observations