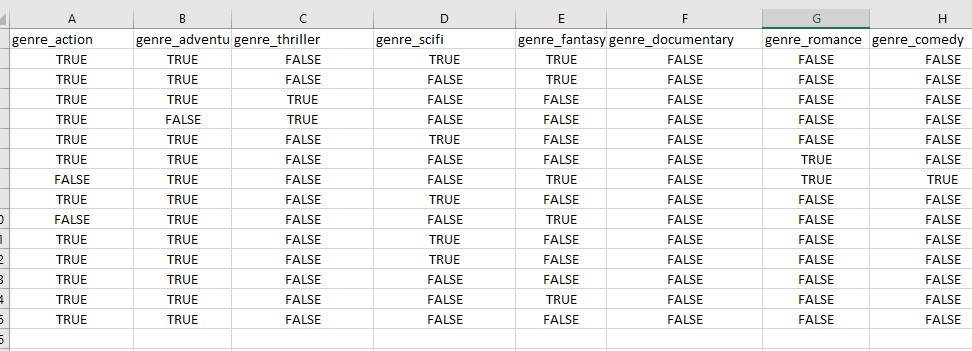
Good afternoon colleagues,genre that will take a value such as action, drama, sci-fi and their combinations. But as seen in the attached snippet, we have a column corresponding to each genre type, and they take values True, False. The goal is to get rid of all these columns and define a new variable called genre
One option is to use if-else() here but is there any method from tidyverse package. Advice/ feedback is greatly appreciated.
cderv
July 8, 2018, 8:39pm
2
There are several ways to do that using tidyverse tools. If you can provide a reprex , it will be easier to show you how.
What your new genre column will contain ? A concatenated string with all genre ? A vector of genre ? A list ?
I would suggest two approaches:
Replace in each column the TRUE values by the corresponding genre, then create a column to concatenate the strings or create the vector / list
Use a reshaping and filtering (something with gather, separate, filter, mutate) to add a column with row number, pass the column name in one column (several rows for each previous row number), keep only rows where values is true, reshape in one row per original row number creating a column genre.
2 Likes
Thaks for the prompt response.
library(dplyr)
new = read.csv("Book1.csv", header=T, sep=",")
View(new)
I tried to use repex (for the first time) as highlighted on https://www.jessemaegan.com/post/so-you-ve-been-asked-to-make-a-reprex/
cderv
July 9, 2018, 5:50am
4
Thanks for trying.
View open the viewer in RStudio - no need to use it in a reprex.read.csv but in this case you need to provide the csv file. Without the csv file, I do not have the data at hand.dput in base R or datapasta
@EconomiCurtis split this out of FAQ: What's a reproducible example (`reprex`) and how do I do one? .
Curious if you have anything additional to add specifically on "how to prepare your own data for use in a reprex if you can't, or don't know how to reproduce a problem with a built-in dataset."
I think @jessemaegan 's post is about 80% there. The piece it is missing, if your average stack overflow post is any indication, is an explanation about how to prepare your own data for use in a reprex if you can't, or don't know how to reproduce a problem with a built-in dataset.
Some handy things to know for this situation:
deparse()
The ugly as sin, gold standard:
head(my_data, 2) %>%
depa…
You can also recreate your data by hand. tribble can help you.
If you have improvement in mind on the reprex guide or found unclear parts, do not hesitate to tell us!
Leon
July 9, 2018, 6:03am
5
Like so?
set.seed(116647)
get_bools = function(n=10){
return( sample(x = c(TRUE,FALSE), size = n, replace = TRUE) )
}
movie_dat = tibble(genre_action = get_bools(),
genre_adventure = get_bools(),
genre_thriller = get_bools(),
genre_scifi = get_bools(),
genre_fantasy = get_bools(),
genre_documentary = get_bools(),
genre_romance = get_bools(),
genre_comedy = get_bools())
movie_dat
# A tibble: 10 x 8
genre_action genre_adventure genre_thriller genre_scifi genre_fantasy genre_documentary
<lgl> <lgl> <lgl> <lgl> <lgl> <lgl>
1 TRUE TRUE TRUE FALSE TRUE TRUE
2 FALSE FALSE FALSE FALSE FALSE FALSE
3 FALSE TRUE TRUE TRUE TRUE TRUE
4 FALSE TRUE TRUE FALSE TRUE TRUE
5 FALSE TRUE FALSE FALSE TRUE TRUE
6 TRUE FALSE TRUE FALSE TRUE TRUE
7 FALSE TRUE TRUE TRUE TRUE TRUE
8 TRUE FALSE FALSE FALSE FALSE FALSE
9 FALSE FALSE FALSE TRUE FALSE TRUE
10 FALSE TRUE FALSE FALSE TRUE FALSE
# ... with 2 more variables: genre_romance <lgl>, genre_comedy <lgl>
Then we can do the following:
movie_dat %>% gather(genre, bool)
# A tibble: 80 x 2
genre bool
<chr> <lgl>
1 genre_action TRUE
2 genre_action FALSE
3 genre_action FALSE
4 genre_action FALSE
5 genre_action FALSE
6 genre_action TRUE
7 genre_action FALSE
8 genre_action TRUE
9 genre_action FALSE
10 genre_action FALSE
# ... with 70 more rows
This is called converting from wide to long data
Hope it's useful
3 Likes
cderv
July 9, 2018, 6:11am
6
This is a great example on how to create a dummy data.frame to help with the question ! Thanks!
@jayant you now still need to precise what your column genre should look like. something like comma-concatenated genre "action, drama, comedy" if these are TRUE in there respective column ?
1 Like
Leon
July 9, 2018, 11:13am
7
Here is a slight modification of my previous post, in my view the data fits best in long format:
set.seed(116647)
get_bools = function(n=10){
return( sample(x = c(TRUE,FALSE), size = n, replace = TRUE) )
}
movie_dat = tibble(movie_name = paste0("movie_", LETTERS[1:10]),
genre_action = get_bools(),
genre_adventure = get_bools(),
genre_thriller = get_bools(),
genre_scifi = get_bools(),
genre_fantasy = get_bools(),
genre_documentary = get_bools(),
genre_romance = get_bools(),
genre_comedy = get_bools())
movie_dat %>% gather(genre, bool, -movie_name) %>% filter(bool) %>%
select(movie_name, genre)
# A tibble: 37 x 2
movie_name genre
<chr> <chr>
1 movie_A genre_action
2 movie_F genre_action
3 movie_H genre_action
4 movie_A genre_adventure
5 movie_C genre_adventure
6 movie_D genre_adventure
7 movie_E genre_adventure
8 movie_G genre_adventure
9 movie_J genre_adventure
10 movie_A genre_thriller
# ... with 27 more rows
3 Likes
jayant
July 10, 2018, 1:16am
8
Good afternoon!
Thanks for your advice and helpful comments. I was able to get the data in long format as shown above. I used the following code to achieve it.
selected_data <- select (movie_renamed,movie_title,action,adventure,thriller,scifi,fantasy,
documentary,romance,comedy,animation,family,drama,horror)
melted_data <- melt(selected_data,"movie_title")
melted_data_filtered <- melted_data %>% filter(value=='TRUE')
And I obtain the following data.
movie_data = tibble(movie_title=c("Avatar","Spectre","Avatar"),genre=c("action","fantasy","scifi"))
tibble: 3 × 2
movie_title genre
<chr> <chr>
1 Avatar action
2 Spectre fantasy
3 Avatar scifi
But my goal is to avoid repetition of movie title and have a concatenated list of the genre, for example;
Avatar scifi+action
In other words, we need to go back to wide format with two columns, movie_title and genre. Can I kindly get help here? thanks
Leon
July 10, 2018, 6:12am
9
You could do something along the lines of this then:
set.seed(116647)
get_bools = function(n=10){
return( sample(x = c(TRUE,FALSE), size = n, replace = TRUE) )
}
movie_dat = tibble(genre_action = get_bools(),
genre_adventure = get_bools(),
genre_thriller = get_bools(),
genre_scifi = get_bools(),
genre_fantasy = get_bools(),
genre_documentary = get_bools(),
genre_romance = get_bools(),
genre_comedy = get_bools())
movie_dat %>% apply(1, function(x){ return(names(x[x])) }) %>%
lapply(paste, collapse='+') %>% unlist
[1] "genre_action+genre_adventure+genre_thriller+genre_fantasy+genre_documentary+genre_romance"
[2] "genre_comedy"
[3] "genre_adventure+genre_thriller+genre_scifi+genre_fantasy+genre_documentary"
[4] "genre_adventure+genre_thriller+genre_fantasy+genre_documentary+genre_comedy"
[5] "genre_adventure+genre_fantasy+genre_documentary"
[6] "genre_action+genre_thriller+genre_fantasy+genre_documentary+genre_comedy"
[7] "genre_adventure+genre_thriller+genre_scifi+genre_fantasy+genre_documentary"
[8] "genre_action+genre_comedy"
[9] "genre_scifi+genre_documentary+genre_romance"
[10] "genre_adventure+genre_fantasy"
cderv
July 10, 2018, 6:16am
10
You can use the tidyverse to achieve what you want. It is the same as @Leon answer but only with a tidyverse pipe
set.seed(116647)
get_bools = function(n=10){
return( sample(x = c(TRUE,FALSE), size = n, replace = TRUE) )
}
library(tidyverse)
movie_dat = tibble(movie_name = paste0("movie_", LETTERS[1:10]),
genre_action = get_bools(),
genre_adventure = get_bools(),
genre_thriller = get_bools(),
genre_scifi = get_bools(),
genre_fantasy = get_bools(),
genre_documentary = get_bools(),
genre_romance = get_bools(),
genre_comedy = get_bools())
movie_dat %>%
gather(genre, bool, -movie_name) %>%
filter(bool) %>%
select(-bool) %>%
separate(genre, c('to_delete', 'genre')) %>%
select(-to_delete) %>%
group_by(movie_name) %>%
summarise(genre = paste(genre, collapse = "+"))
#> # A tibble: 10 x 2
#> movie_name genre
#> <chr> <chr>
#> 1 movie_A action+adventure+thriller+fantasy+documentary+romance
#> 2 movie_B comedy
#> 3 movie_C adventure+thriller+scifi+fantasy+documentary
#> 4 movie_D adventure+thriller+fantasy+documentary+comedy
#> 5 movie_E adventure+fantasy+documentary
#> 6 movie_F action+thriller+fantasy+documentary+comedy
#> 7 movie_G adventure+thriller+scifi+fantasy+documentary
#> 8 movie_H action+comedy
#> 9 movie_I scifi+documentary+romance
#> 10 movie_J adventure+fantasy
Created on 2018-07-10 by the reprex package (v0.2.0).
jayant
July 10, 2018, 10:04pm
11
Thank you for your ideas, @cderv and @Leon . I was able to achieve my goal using a blend of both ideas;
melted_data <- melt(selected_data,"movie_title")
melted_data_filtered <- melted_data %>% filter(value=='TRUE')
melted_data_filtered$value <- melted_data_filtered$variable
melted_data_filtered <- melted_data_filtered %>% select(-variable)
melted_data_filtered_sorted <- melted_data_filtered %>% arrange(movie_title)
data_filtered <- melted_data_filtered_sorted %>% group_by(movie_title)%>%
summarise(genre = paste(value, collapse = "+"))
I just gave a code snippet here, which is working for me. As seen, after melting I tried to use group_by to do the concatenation. thanks for the assistance.
1 Like