I have a model as follow:
- Here is what the data frame looks like after I tailored down the unnecessary details that would not make sense in my model:
str(df)
'data.frame': 991205 obs. of 6 variables:
$ cust_prog_level : Factor w/ 14 levels "B","C","D","E",..: 9 7 5 9 10 5 5 12 9 10 ...
$ CUST_REGION_DESCR : Factor w/ 8 levels "CORPORATE REGION",..: 3 3 3 6 3 3 3 3 3 3 ...
$ ACCTG_MONTH_KEY : int 201801 201709 201804 201803 201801 201705 201712 201801 201803 201705 ...
$ Sales : num 150.2 75.1 76.2 135 150.2 ...
$ New_Product_Type : Factor w/ 2 levels "Not_PL","PL": 1 1 1 1 1 1 1 1 1 1 ...
$ MAJOR_CATEGORY_KEY: Factor w/ 26 levels "AIR","AML","ANS",..: 23 23 23 23 23 23 23 23 23 23 ...
-
My model is as follow:
set.seed(500) nobs = nrow(df) train <- sample(nrow(df), 0.7*nobs) test <- setdiff(seq_len(nrow(df)), train) # Build the Decision Tree model. fit <- rpart(New_Product_Type~., data=df[train, ], method="class") fancyRpartPlot(fit, main="Decision Tree Graph")
My goal is to see from the analysis result, how can I make a decision which alley to invest in order to have more people choose "PL" instead of "No_PL".
Here is the summary:
Call:
rpart(formula = New_Product_Type ~ ., data = df[train, ], method = "class")
n= 693843
CP nsplit rel error xerror xstd
1 0.2127376 0 1.0000000 1.0000000 0.001963200
2 0.1113809 1 0.7872624 0.7872624 0.001809865
3 0.0100000 3 0.5645007 0.5645377 0.001590637
Variable importance
MAJOR_CATEGORY_KEY Sales cust_prog_level
74 25 1
Node number 1: 693843 observations, complexity param=0.2127376
predicted class=Not_PL expected loss=0.2721696 P(node) =1
class counts: 505000 188843
probabilities: 0.728 0.272
left son=2 (423101 obs) right son=3 (270742 obs)
Primary splits:
MAJOR_CATEGORY_KEY splits as LRRRLRRRLLLLLLLLLRLLLLLL-R, improve=80999.46000, (0 missing)
Sales < 28.655 to the right, improve=58633.41000, (0 missing)
cust_prog_level splits as LLLLLLLLRLLLRR, improve= 2998.43000, (0 missing)
CUST_REGION_DESCR splits as LLRRRRRL, improve= 725.28710, (0 missing)
ACCTG_MONTH_KEY < 201706.5 to the left, improve= 80.10278, (0 missing)
Surrogate splits:
Sales < 28.645 to the right, agree=0.706, adj=0.246, (0 split)
cust_prog_level splits as LLLLLLLLLLLLLR, agree=0.613, adj=0.009, (0 split)
Node number 2: 423101 observations
predicted class=Not_PL expected loss=0.07890551 P(node) =0.6097936
class counts: 389716 33385
probabilities: 0.921 0.079
Node number 3: 270742 observations, complexity param=0.1113809
predicted class=PL expected loss=0.4258076 P(node) =0.3902064
class counts: 115284 155458
probabilities: 0.426 0.574
left son=6 (203647 obs) right son=7 (67095 obs)
Primary splits:
MAJOR_CATEGORY_KEY splits as -RRL-LLR---------L-------L, improve=25580.510000, (0 missing)
Sales < 30.31 to the right, improve=23028.650000, (0 missing)
cust_prog_level splits as LLLLLLLLRLLLRR, improve= 1592.459000, (0 missing)
CUST_REGION_DESCR splits as LLRRRRRL, improve= 338.500700, (0 missing)
ACCTG_MONTH_KEY < 201801.5 to the right, improve= 3.721797, (0 missing)
Surrogate splits:
Sales < 7.095 to the right, agree=0.812, adj=0.241, (0 split)
cust_prog_level splits as LLLLLLLLLLLLRL, agree=0.752, adj=0.000, (0 split)
Node number 6: 203647 observations, complexity param=0.1113809
predicted class=Not_PL expected loss=0.4494346 P(node) =0.2935059
class counts: 112121 91526
probabilities: 0.551 0.449
left son=12 (95969 obs) right son=13 (107678 obs)
Primary splits:
Sales < 57.265 to the right, improve=10319.280000, (0 missing)
cust_prog_level splits as LLLLLLLLRLRLLR, improve= 1514.172000, (0 missing)
CUST_REGION_DESCR splits as LLRRLRRL, improve= 204.100600, (0 missing)
MAJOR_CATEGORY_KEY splits as ---R-LL----------R-------R, improve= 86.075000, (0 missing)
ACCTG_MONTH_KEY < 201706.5 to the left, improve= 5.466954, (0 missing)
Surrogate splits:
cust_prog_level splits as RRLRRLLRRLRRLR, agree=0.561, adj=0.068, (0 split)
MAJOR_CATEGORY_KEY splits as ---L-LL----------R-------R, agree=0.539, adj=0.022, (0 split)
Node number 7: 67095 observations
predicted class=PL expected loss=0.04714211 P(node) =0.09670055
class counts: 3163 63932
probabilities: 0.047 0.953
Node number 12: 95969 observations
predicted class=Not_PL expected loss=0.2808303 P(node) =0.1383152
class counts: 69018 26951
probabilities: 0.719 0.281
Node number 13: 107678 observations
predicted class=PL expected loss=0.4002953 P(node) =0.1551907
class counts: 43103 64575
probabilities: 0.400 0.600
n= 693843
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 693843 188843 Not_PL (0.72783036 0.27216964)
2) MAJOR_CATEGORY_KEY=AIR,ASP,CBL,CEM,CMP,CRN,END,FNP,GYP,HND,IMP,OTH,P&P,PRE,RTC,SME,UCL 423101 33385 Not_PL (0.92109449 0.07890551) *
3) MAJOR_CATEGORY_KEY=AML,ANS,ASE,B&D,BLE,C&P,INS,XRY 270742 115284 PL (0.42580760 0.57419240)
6) MAJOR_CATEGORY_KEY=ASE,B&D,BLE,INS,XRY 203647 91526 Not_PL (0.55056544 0.44943456)
12) Sales>=57.265 95969 26951 Not_PL (0.71916973 0.28083027) *
13) Sales< 57.265 107678 43103 PL (0.40029532 0.59970468) *
7) MAJOR_CATEGORY_KEY=AML,ANS,C&P 67095 3163 PL (0.04714211 0.95285789) *
Here is the graph:
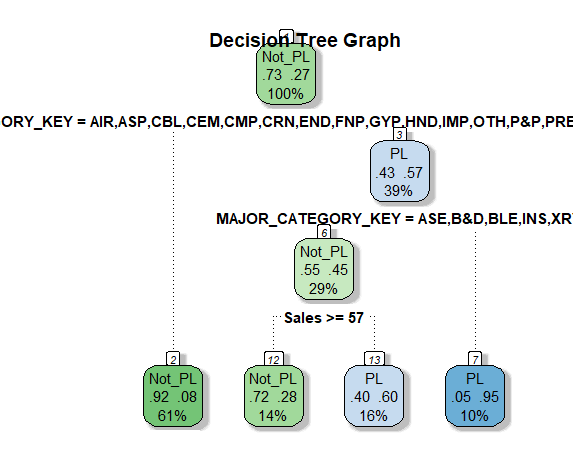
Here are my questions:
Question 1: From Node number 1, what does this mean?
left son=2 (423101 obs) right son=3 (270742 obs)
How to interpret the Primary Splits?
Primary splits:
MAJOR_CATEGORY_KEY splits as LRRRLRRRLLLLLLLLLRLLLLLL-R, improve=80999.46000, (0 missing)
Sales < 28.655 to the right, improve=58633.41000, (0 missing)
cust_prog_level splits as LLLLLLLLRLLLRR, improve= 2998.43000, (0 missing)
CUST_REGION_DESCR splits as LLRRRRRL, improve= 725.28710, (0 missing)
ACCTG_MONTH_KEY < 201706.5 to the left, improve= 80.10278, (0 missing)
Surrogate splits:
Sales < 28.645 to the right, agree=0.706, adj=0.246, (0 split)
cust_prog_level splits as LLLLLLLLLLLLLR, agree=0.613, adj=0.009, (0 split)
For MAJOR_CATEGORY_KEY*, there are 26 levels:
> levels(MAJOR_CATEGORY_KEY)
[1] "AIR " "AML " "ANS " "ASE " "ASP " "B&D " "BLE " "C&P " "CBL " "CEM " "CMP " "CRN " "END "
[14] "FNP " "GYP " "HND " "IMP " "INS " "OTH " "P&P " "PRE " "RTC " "SME " "UCL " "UNK " "XRY "
so can I assume that in the split criteria which have a string of:
MAJOR_CATEGORY_KEY splits as LRRRLRRRLLLLLLLLLRLLLLLL-R, improve=80999.46000, (0 missing)
LRRRR etc. correspond to where each level in the "MAJOR CATEGORY KEY" goes, i.e first level goes left, second level goes right etc.?
Question 2: For Node Number 2
Node number 1: 693843 observations, complexity param=0.2127376
predicted class=Not_PL expected loss=0.2721696 P(node) =1
class counts: 505000 188843
probabilities: 0.728 0.272
left son=2 (423101 obs) right son=3 (270742 obs)
Primary splits:
MAJOR_CATEGORY_KEY splits as LRRRLRRRLLLLLLLLLRLLLLLL-R, improve=80999.46000, (0 missing)
Sales < 28.655 to the right, improve=58633.41000, (0 missing)
cust_prog_level splits as LLLLLLLLRLLLRR, improve= 2998.43000, (0 missing)
CUST_REGION_DESCR splits as LLRRRRRL, improve= 725.28710, (0 missing)
ACCTG_MONTH_KEY < 201706.5 to the left, improve= 80.10278, (0 missing)
Surrogate splits:
Sales < 28.645 to the right, agree=0.706, adj=0.246, (0 split)
cust_prog_level splits as LLLLLLLLLLLLLR, agree=0.613, adj=0.009, (0 split)
Node number 2: 423101 observations
predicted class=Not_PL expected loss=0.07890551 P(node) =0.6097936
class counts: 389716 33385
probabilities: 0.921 0.079
The P(node) =0.6097936 means the chance I will get from node 1 to node 2 is about 61%. From Node number 1 splitting criteria, if Sales >=28.645, then I will go to the left. Combining these two information, I would say there is about 39% chance that if the Sales < 28.645, there is only 39% chance I will go to the right branch??
Does it sound right?
Question 3: What does a surrogate split do?