Prof Brian Ripley sent out the email below to a few R package developers ( including @davis for the slider package), giving us 14 days to solve problems reported by valgrind.
I'd like to ask if anyone here might be able to help developers figure out what to do about this message. I hope that our discussion here might be helpful to all the developers who received the email, as well as future developers who might eventually receive such a message.
Here are my questions:
What is the general problem here? How important are these errors?
How can we find the source of each error? What are we (R package authors) supposed to do about it?
What's the quickest way to set up a local environment to reproduce the reported errors?
The email:
That is
Carlson MatchIt PheVis boodist ggrepel jacobi lavacreg round secsse
slider smerc
see the logs at
https://www.stats.ox.ac.uk/pub/bdr/memtests/valgrindExtra/ with
reproduction details in the README.txt
Compiling with valgrind often changes computations or spills results
from registers to memory (which on x86_64 reduces the f/p precision).
Some of you are relying on arithmetic preserving the status of NA as a
special NaN.
Reports like
identical(pos1, pos2) is not TRUE
zcompare(fzones1, fzones1b, lprimes) is not TRUE
are maximally unhelpful: you have no way of knowing what the values were
on a remote machine.
Please correct before 2023-10-22 to safely retain your package on CRAN.
--
Brian D. Ripley, ripley@stats.ox.ac.uk
Emeritus Professor of Applied Statistics, University of Oxford
In your package, you do some arithmetic in C/C++/Fortran on double values, and you expect that this arithmetic keeps NAs, but that is unfortunately not always true, they might turn into NaN values.
interesting issue; how are such issues typically addresses ? would it be considered too brutish to record the positions of any NA's that its feared might be converted to NaN, and after the external function call returns, forcing NA's back into those positions ?
Yeah, that seems like a good way: keep NAs NAs, and only do the arithmetic operation on the rest of the vector. Of course if the operation is not a simple mapping of a vector, then this can be more complicated.
It matters for some applications, because NA is not the same as NaN:
❯ identical(NA_real_, NaN)
[1] FALSE
Not Rcpp, but maybe you can wait until slider is fixed, to see an example.
Btw. not really a fix, strictly speaking, but to keep your package on CRAN, you can also skip the failing tests on CRAN (temporarily?), e.g. with skip_on_cran() if you are using testthat.
Another developer on the email list replied and said:
The code is supposed to return the degrees of freedom of a Chi² distribution, but with Valgrind it founds -NaN. That makes no sense, I have no idea how to fix that.
I feel the same way as this developer.
There is a lack of clarity about why valgrind is being used in this way, what is the underlying source of the valgrind issue, which users are affected by this issue, and what the package developers are expected to do about it.
Okay, in slider's case the problem was that I was expecting a sum(), mean(), and prod() calculation that involved both NA and NaN to return a precise result - i.e. I was expecting sum(NA, NaN) to return NA.
But if you read the help page of ?NA then you'll see:
Numerical computations using NA will normally result in NA : a possible exception is where NaN is also involved, in which case either might result (which may depend on the R platform). However, this is not guaranteed and future CPUs and/or compilers may behave differently. Dynamic binary translation may also impact this behavior (with valgrind, computations using NA may result in NaN even when no NaN is involved).
The last line is particularly interesting, where it is saying that on valgrind you could even see sum(NA) returning NaN.
It seems that on valgrind my specific tests were returning NaN when I expected NA or vice versa.
Anyways, I was using expect_identical() in my tests, which tests for the exact difference between NA and NaN. The easiest fix I could come up with was to use expect_equal() instead, which treats NA and NaN as equivalent values, while still actually comparing any other non-missing values in the vector.
I think this will probably apply to a few of us who got that email. Switching from expect_true(identical(x, y)) or expect_identical(x, y) to expect_equal(x, y) is probably an easy fix.
I don't have any good advice for the developer who responded with "The code is supposed to return the degrees of freedom of a Chi² distribution, but with Valgrind it founds -NaN." besides just using skip_on_cran() for that test and moving on with their life.
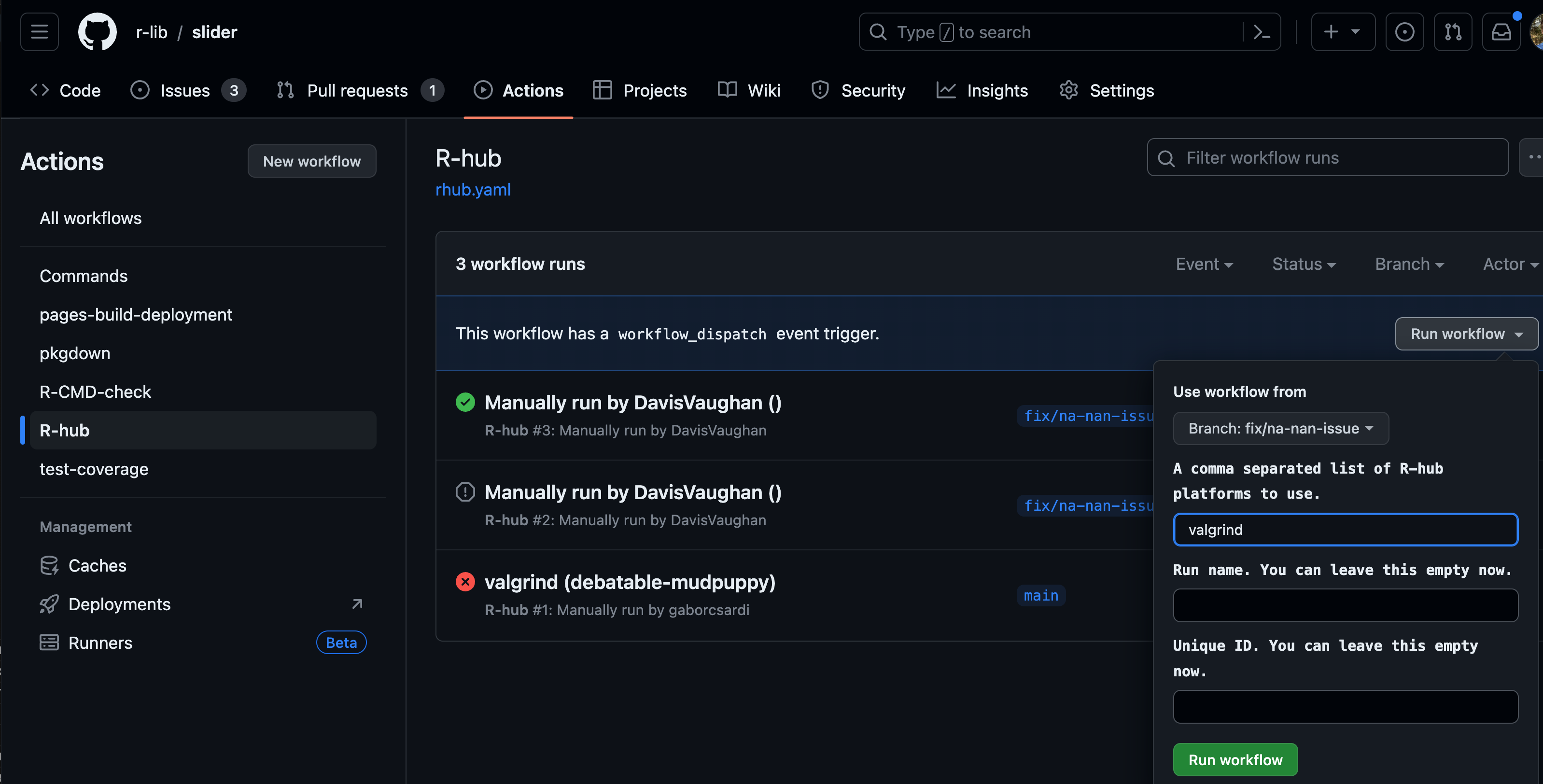
If you do want to test that your fixes pass with Valgrind, you can use this great r-hub workflow file:
As the instructions show (GitHub - r-hub/rhub2: The 'R-hub' package builder, v2) you basically just need to install rhub2 with pak::pak("r-hub/rhub2") and then call rhub2::rhub_setup() to add the workflow file to your package and push that to GitHub. After that you should be able to call rhub2::rhub_check(platforms = "valgrind", branch = "my-branch-name") to start a check.
That didn't immediately work for me though, so, after pushing the workflow file to github, another way is to go to your Actions page and manually trigger the workflow with the valgrind platform and the right branch name.