Hi, I want to know which software can do de-aggregation of data ? For example I have got aggregated data and want to go to raw/individual data, in R I could use uncount() function, but is it possible to do it in other statistical software ?
Hi, I want to know which software can do de-aggregation of data ? For example I have got aggregated data and want to go to raw/individual data, in R I could use uncount() function, but is it possible to do it in other statistical software ?
I would expect this to be achievable in every programming language... perhaps you could narrow your question?
I would like to do it somehow in SPSS. Practically in every software there is aggregate function, but going back
to raw data is not possible. I work often with SPSS and I can import data (sav file) into R and uncount() it and then save it as sav file and be back in SPSS. The thing is that in SPSS factors can be numbered starting from 0 but in R indexing starts from 1 so I have to correct it in SPSS.
Is there a way maybe to start numbering levels from 0 in R or is it possible to uncount data in SPSS (using syntax) ?
I checked Jamovi and Jasp as well but did not find such an option there.
This is a little kludgey, but if the factor in R is named V you could do
V1<-as.numeric(V)-1
and then save V1 to SPSS.
It works but it removes factor's labels. What to do to retain labels ?
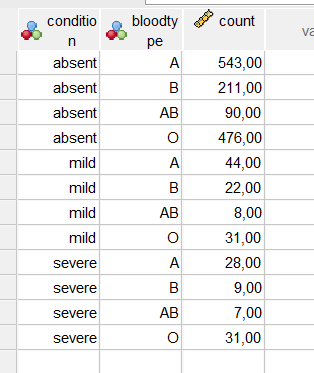
danne <- structure(list(condition = structure(c(1L, 1L, 1L, 1L, 2L, 2L,
2L, 2L, 3L, 3L, 3L, 3L), levels = c("absent", "mild", "severe"
), class = "factor"), bloodtype = structure(c(1L, 2L, 3L, 4L,
1L, 2L, 3L, 4L, 1L, 2L, 3L, 4L), levels = c("A", "B", "AB", "O"
), class = "factor"), count = c(543, 211, 90, 476, 44, 22, 8,
31, 28, 9, 7, 31)), class = "data.frame", row.names = c(NA, -12L
), variable.labels = structure(character(0), names = character(0)), codepage = 1252L)
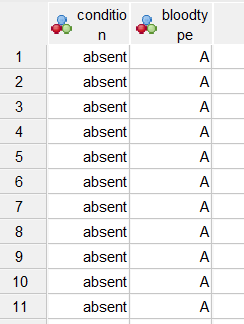
so basically I am asking, is this possible:
I feel you might get more help posting on an SPSS forum.
I havent used spss, so i asked LLM for example to uncount using loop.
I asked to start with a row of a representing one entry with an associated value 2, and a row for b representing 2 entries with a value 5.
DATA LIST FREE / Item (A1) Count Value.
BEGIN DATA
a 1 2
b 2 5
END DATA.
SORT CASES BY Count (D).
VECTOR newItem(100) / newValue(100).
COMPUTE idx = 1.
LOOP #i = 1 TO N.
+ DO REPEAT #j = 1 TO Count.
+ COMPUTE newItem(idx) = Item.
+ COMPUTE newValue(idx) = Value.
+ COMPUTE idx = idx + 1.
+ END REPEAT.
END LOOP.
EXECUTE.
VARSTOCASES /MAKE Item FROM newItem1 TO newItem100 /MAKE Value FROM newValue1 TO newValue100 /INDEX=idx.
SELECT IF NOT MISSING(Item).
EXECUTE.Thank you,
how would it go for my data :
What should I copy/paste into that syntax of yours ?
Nobody knows the answer on that forum.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.
If you have a query related to it or one of the replies, start a new topic and refer back with a link.
