Hey there!
I'm new to R Studio and currently trying to remake a data analysis plus visualisation I already did in Excel/Origin.
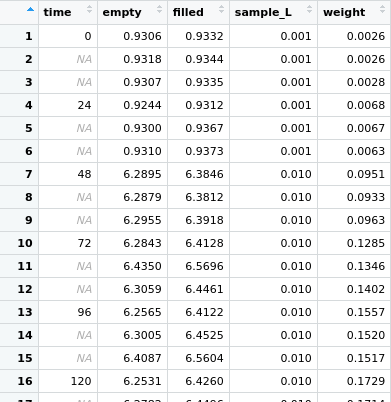
I'm doing this because I want to practice, so I can use RStudio for future data analysis. My data will be of the sort that I take samples at certain times from different batches and create several sets of data according to each "time stamp", including 3 replicates at each time point. It currently looks smt like this:
Now, I wonder if there is a better way of sorting this data in the first place. I will need to determine mean and standard error out of the 3 replicates, but I#m not sure how to calculate it for every 3 rows and the next 3 and the next. Should I try to replace the NA in time, since the time would be the same as above? What do you guys think would be the easiest/fastest way to tackle data like this? Could you show me how it should look like to make things easier?
yes; your data should be as accurate to the truth of the world as possible. its not the case that of your 3 samples taken at the same time as each other you only know the time that the first of the set of three was taken, you know the time for all three and its the same 0 time ; or the same 24 etc.
have your time column be accurate, and you can add an additional field/column to make each row uniquely identifiable by having a simple id i.e. 1,2,3 etc.
This would give you freedom to transform the data and have a solid base from which to do so.
If the NA time is the same as the last non-NA time above and you want to replace the NA with the last known value, take a look at tidyr::fill(). You can pass your data through something like this:
library(tidyr)
fill(your_data, time, .direction = "down")
With the time column filled, you'll be able to dplyr::summarise() by the distinct values in the time column. e.g.