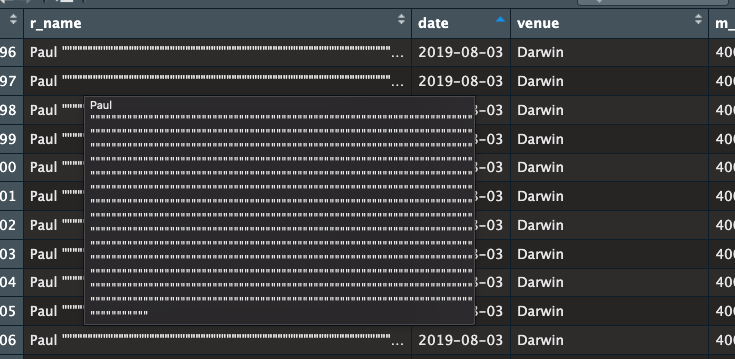
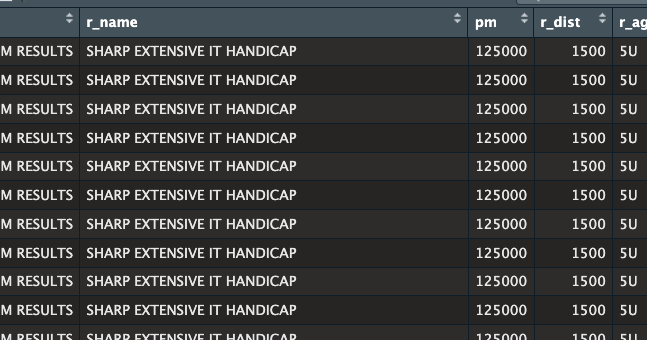
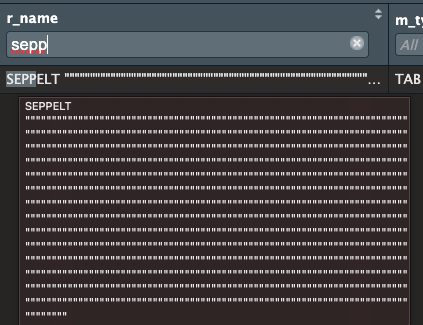
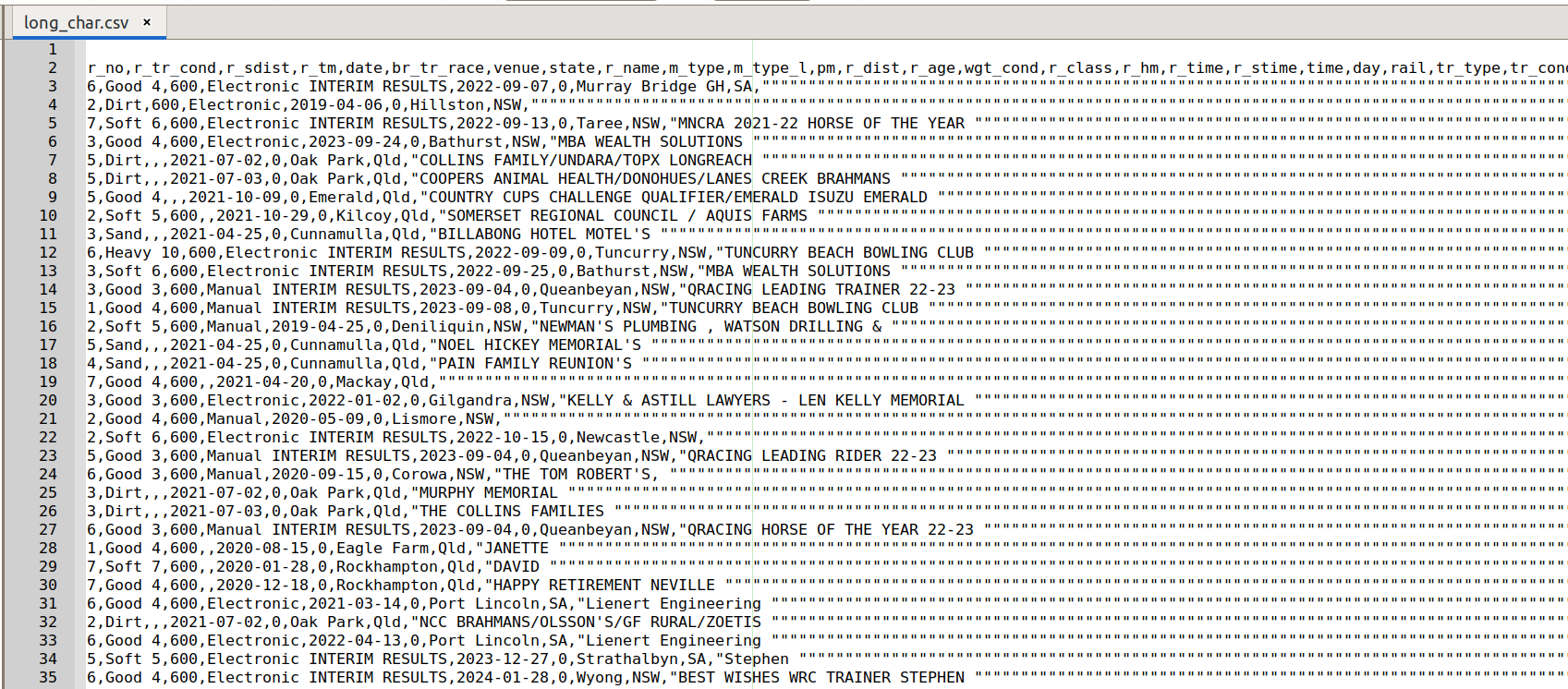
It started out like the following and multiplied.
I just recreated the file without removing the double quotations. I now make sure I remove them.
structure(list(track_n = c("Main", "Main", "Main", "Main", "Main",
"Main", "Main", "Main", "Main"), tr_ty = c("Turf", "Turf", "Turf",
"Turf", "Turf", "Turf", "Turf", "Turf", "Turf"), r_tr_cond = c("Good 4",
"Good 4", "Good 4", "Good 4", "Good 4", "Good 4", "Good 4", "Good 4",
"Good 4"), r_sdist = c(600L, 600L, 600L, 600L, 600L, 600L, 600L,
600L, 600L), r_tm = c("Electronic", "Electronic", "Electronic",
"Electronic", "Electronic", "Electronic", "Electronic", "Electronic",
"Electronic"), r_no = 1:9, date = structure(c(17901, 17901, 17901,
17901, 17901, 17901, 17901, 17901, 17901), class = "Date"), br_tr_race = c(0L,
0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L), venue = c("Ascot", "Ascot",
"Ascot", "Ascot", "Ascot", "Ascot", "Ascot", "Ascot", "Ascot"
), state = c("WA", "WA", "WA", "WA", "WA", "WA", "WA", "WA",
"WA"), r_name = c("CROWN PERTH PLATE", "TABTOUCH - BETTER YOUR BET HANDICAP",
"MUMM CHAMPAGNE HANDICAP", "AMELIA PARK HANDICAP", "FURPHY-SUMMER SCORCHER",
"MRS MAC'S-LA TRICE CLASSIC", "ASCEND SALES HANDICAP", "TABTOUCH-PERTH CUP",
"SEPPELT \"THE DRIVES\" HANDICAP"), m_type = c("TAB", "TAB",
"TAB", "TAB", "TAB", "TAB", "TAB", "TAB", "TAB"), m_type_l = c("Metro",
"Metro", "Metro", "Metro", "Metro", "Metro", "Metro", "Metro",
"Metro"), pm = c(70000, 70000, 70000, 70000, 1e+05, 150000, 70000,
5e+05, 50000), r_dist = c(1000L, 1600L, 1600L, 2200L, 1000L,
1800L, 1100L, 2400L, 1200L), r_age = c("2", "3", "3U", "3U",
"3U", "3U", "3U", "3U", "3U"), wgt_cond = c("SWP", "HCP", "HCP",
"HCP", "QTY", "SWP", "HCP", "QTY", "HCP"), r_class = c("~", "~",
"BM72", "BM66", "LISTED", "GRP3", "BM66", "GRP2", "1MW"), r_hm = c(NA_character_,
NA_character_, NA_character_, NA_character_, NA_character_, NA_character_,
NA_character_, NA_character_, NA_character_), r_time = c(58.96,
96.35, 96.58, 138.5, 57.74, 110.7, 64.97, 148.13, 70.85), r_stime = c(34.56,
35.61, 35.42, 36.27, 33.09, 35.13, 34.8, 36.52, 35.16), r_id = 5134154:5134162,
time = c("12:08PM", "12:46PM", "1:26PM", "2:06PM", "2:43PM",
"3:18PM", "3:55PM", "4:35PM", "5:15PM"), m_id = c(4018099L,
4018099L, 4018099L, 4018099L, 4018099L, 4018099L, 4018099L,
4018099L, 4018099L), day = c("Saturday", "Saturday", "Saturday",
"Saturday", "Saturday", "Saturday", "Saturday", "Saturday",
"Saturday"), rail = c("Out 5 metres.", "Out 5 metres.", "Out 5 metres.",
"Out 5 metres.", "Out 5 metres.", "Out 5 metres.", "Out 5 metres.",
"Out 5 metres.", "Out 5 metres."), tr_type = c("Turf", "Turf",
"Turf", "Turf", "Turf", "Turf", "Turf", "Turf", "Turf"),
tr_cond = c("Good", "Good", "Good", "Good", "Good", "Good",
"Good", "Good", "Good"), weather = c("Fine", "Fine", "Fine",
"Fine", "Fine", "Fine", "Fine", "Fine", "Fine"), penetrometer = c(6.4,
6.4, 6.4, 6.4, 6.4, 6.4, 6.4, 6.4, 6.4), tr_info = c(NA_character_,
NA_character_, NA_character_, NA_character_, NA_character_,
NA_character_, NA_character_, NA_character_, NA_character_
), dual_tr = c("N", "N", "N", "N", "N", "N", "N", "N", "N"
)), row.names = c(NA, -9L), class = c("tbl_df", "tbl", "data.frame"
))