If you'd like to start a new discussion under Data Science Leaders, go to #industry, and click "New Topic".
To follow new Data Science Leaders posts, be sure to at least click "Watching First Post" on #industry
Recap
Here's a recap of some of the activity related to Data Science Leaders at rstudio::global(2021)
Poll - What do you see as the primary role of data scientists in your organization?
Lou Bajuk to Data Science Leaders - January 21st, 10:47 AM
One of the things we often have conversations with team leads about is what the role of the data scientist is in your organization. (We wrote some about this in this blog post: The Role of the Data Scientist - Posit). I am curious, what do you see as the primary role of data scientists in your organization? Feel free to add comments to expand on this.
Poll - Biggest Challenges
Alex Gold to Data Science Leaders - January 21st, 8:04 AM
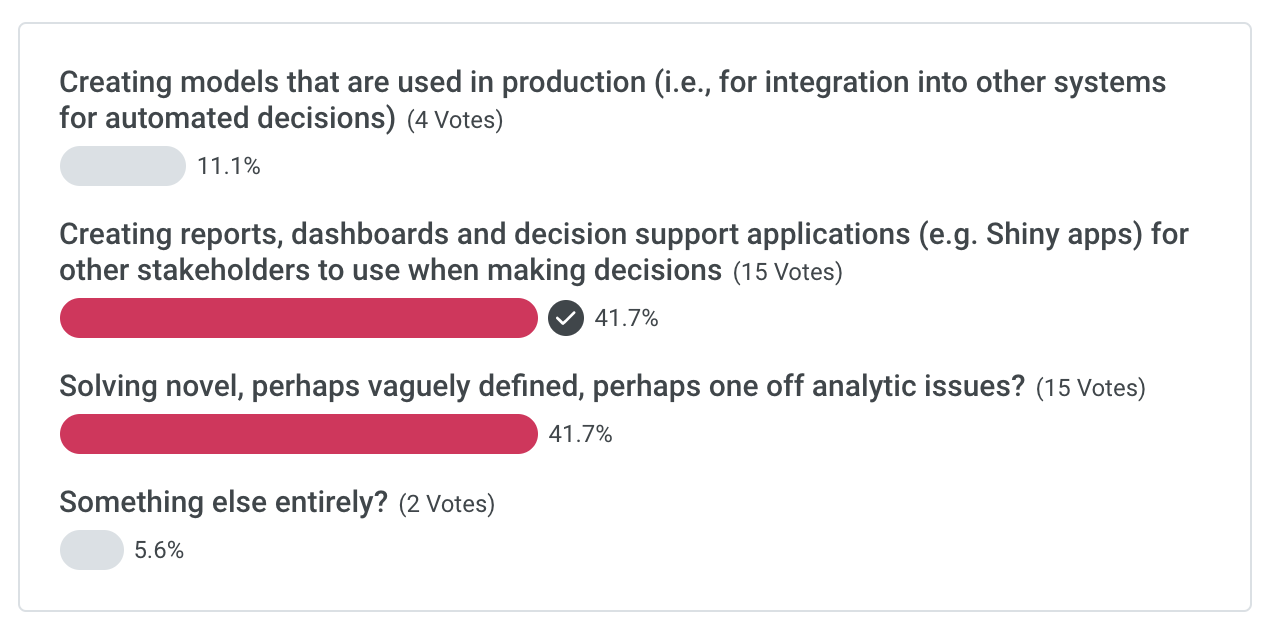
Hey Data Science Leads! Welcome to RStudio::global!! Let's lead off with a poll -- what's your biggest challenge as a data science team lead?

Alex Gold - Please comment with any details you want to share -- or what else entirely is your biggest challenge!
Anne - January 21st, 8:42 AM
deploying trained models at scale. There's a wealth of options to build extremely well-performing sophisticated models, but using those in production on not even very large data streams is a challengeAlex - Hi Anne -- that's a great point. What's the primary challenge for your team? Is it finding a place to deploy? Data processing speed? Figuring out the right architecture?
Anne - Alex- it's several things - there is a very high level of sophistication available when quickly (or less quickly) evaluating models in R or Python, but beyond model evaluation i find the infrastructure to save and deploy models in production lacking; most models do not scale well. So we now evaluate in R, but then translate models to scala/Spark for prod, using deeplearning4j/keras for deeplearning models. It's a bit awkward.
(this is for sequence classification on about 3k/s of data, so not even that much)
Katelyn - As part of a team of self-taught R/Python programmers, we're struggling to use git/BitBucket, code review, etc as means of collaboration. None of us have a CS background so a lot of programming best practices (unit tests, error handling) are things we've only barely heard of
Alex Gold - Katelyn Schreyer -- I think that's a super common issue! Thankfully, I always find that I leave conferences with a boatload of new ideas I'm excited to take home.
Daniel - I would have liked to have chosen all of the above!
Stephanie - I selected one however > all of the above < would work too.
Daniel - But really, I have difficulty trying to get data scientists to use what are traditionally software engineering practices. It's a pretty steep curve for some folks, and very different for folks that haven't been exposed to it before.
Daniel - Doing things at scale is also challenging for us. We're good at building POC models, but scaling up to train multiple models across the entire dataset, in a way that doesn't take an obscene amount of training time, is challenging.
Elaine - I find it extremely difficult to find enough focused time to write good code and solve hands-on problems given the array of other management / administrative / leadership responsibilities. I'd love to know how people in leadership roles who also seem to produce really well thought out packages (Emily Riederer, David Robinson, etc) block out the time for this.
Michael - It helps if the scope of the code project is small, or at least a well-contained, small part of a larger project. The time to get started is a big cost when you only have small pockets to work with. Breaking up projects into smaller components often makes them easier to test and more maintainable, too. Sometimes it helps to explicitly block out time in your schedule for development, rather than leaving it for "open" time.
I've also spent a lot of free time at home working on work-related open source projects. I don't recommend that at all. The work is never done, and it led me to burn out.
Do you use any sort of CI/CD processes with your R code?
Daniel to Data Science Leaders - January 21st, 1:11 PM
I have a few questions that I'd also love to hear everyone's ideas about from a team-lead perspective. I think they're good to get us talking/writing, but I'm also genuinely curious.
Do you use any sort of CI/CD processes with your R code?
How do you structure code reviews and where do you fit them into the process?
How do you balance working on reducing tech debt (and or infrastructure improvements) against working on features more visible to end-users?
Colin Gillespie -
We use a lot of CI/CD internally and with our clients.Internally, we use GitLab and use CI for everything, e.g. package checking, spell checks, looking for missing full stops in table captions! With clients, pretty much everything.
Code Reviews: our strict CI tries to minimise the time spent on code reviews.
Happy to chat more
Daniel -
Thanks for the input, Colin Gillespie ! Was it hard to get buy-in/acceptance for CI? People on the team are still pretty fresh in that regard, so it's a challenge for me to get people more bought in.
Colin
Acceptance - I'm in charge so everyone was happyMore seriously, when you initially implement CI, it (the CI) will have bugs. So you need to be very responsive to fixing it, otherwise people will hate it (and you).
For code reviews, we now disable push direct to master. I think we all suffer from "it's only a little change, so I'll just push".
For us, CI saves us so much time. For example, we have ~30 repos with training materials. You could clone any one of these repos, and run one command and everything will just work - thanks to CI
Daniel - Appreciate the comments, Colin Gillespie !
Francisco
I used to use travis and similar. Now I'm using just github actions.
- lint code
- test coverage
- check builds
- check for Rcpp possible security issues with CodeQL
Darya - With code review, we implemented it in our (data science consultancy at a Uni) team last year, and the key motivation (for team members) was that every project had a secondary analyst who could use the code review as an opportunity to upskill in the methods the first analyst was using. They fit in along the analysis pathway, usually when the core analyst requests one (because as with much consulting, work can be quite sporadic).
Katrina -
I am an IC (engineer), but here's my take:Do you use any sort of CI/CD processes with your R code?
Yes! Github + Jenkins. We use jenkins both for CI and scheduled jobs. We have an internal package that we build and run check in CI. We also check yaml files. We have some unit tests, but as much as others.
How do you structure code reviews and where do you fit them into the process?
We have a github template that has a checklist for requesters (with things like "my branch is fully rebased") and a checklist for reviewers (with things like "I understand what this code is doing will enough to fix it if it breaks.", "I have reviewed the data resulting from this code") We don't check every checkbox with every review, it represents more of an "ideal" review, but having it
ow do you balance working on reducing tech debt (and or infrastructure improvements) against working on features more visible to end-users?
Our team reserves a certain % of bandwidth each quarter for tech debt reduction. Also, when we introduce new tech debt, we have it sized and documented in our Backlog, not just in our minds.