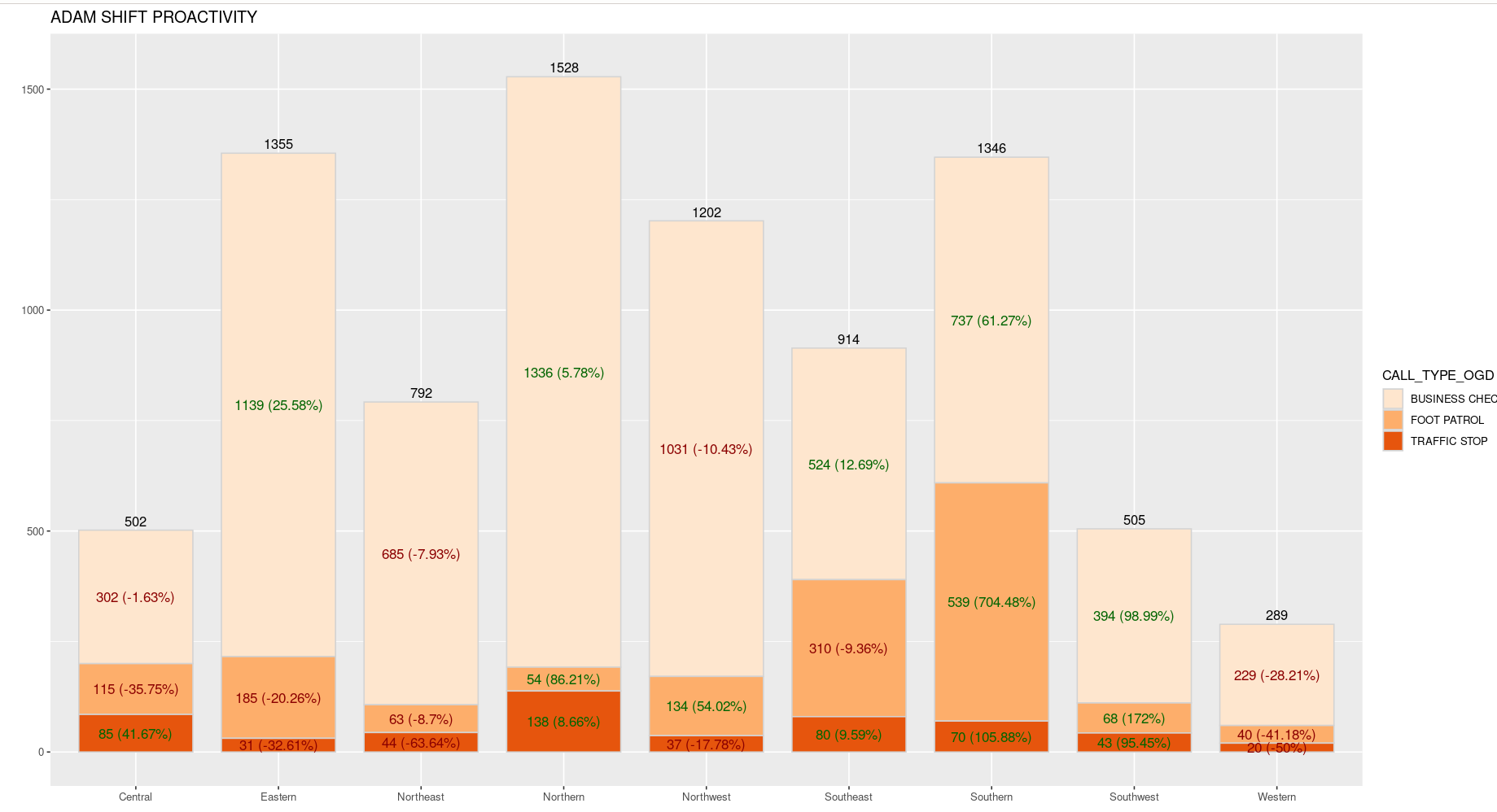
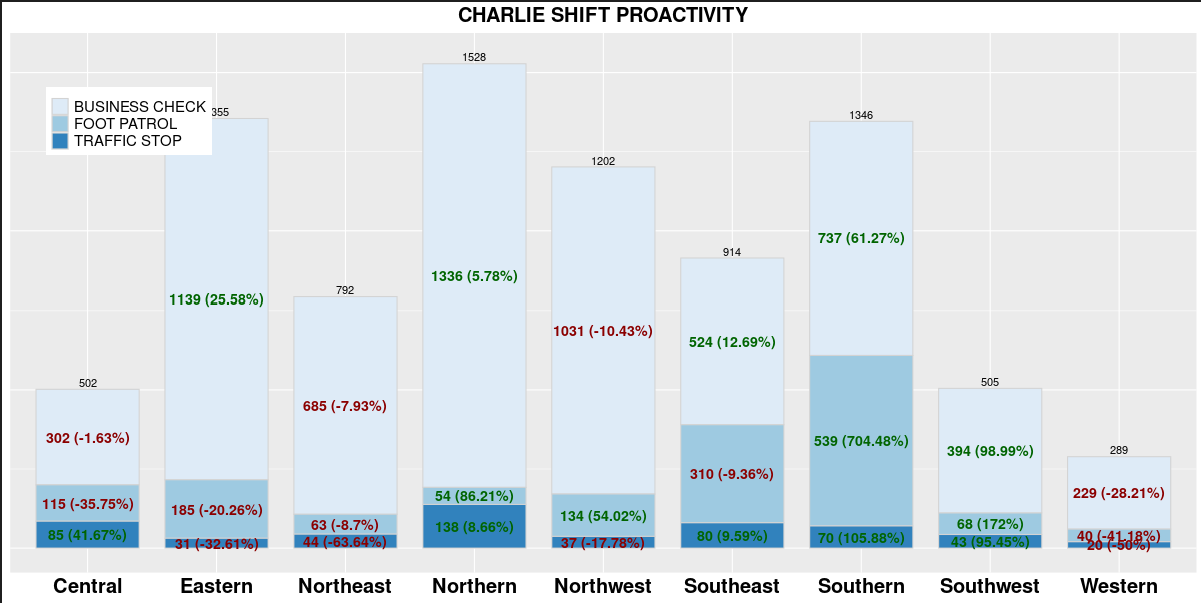
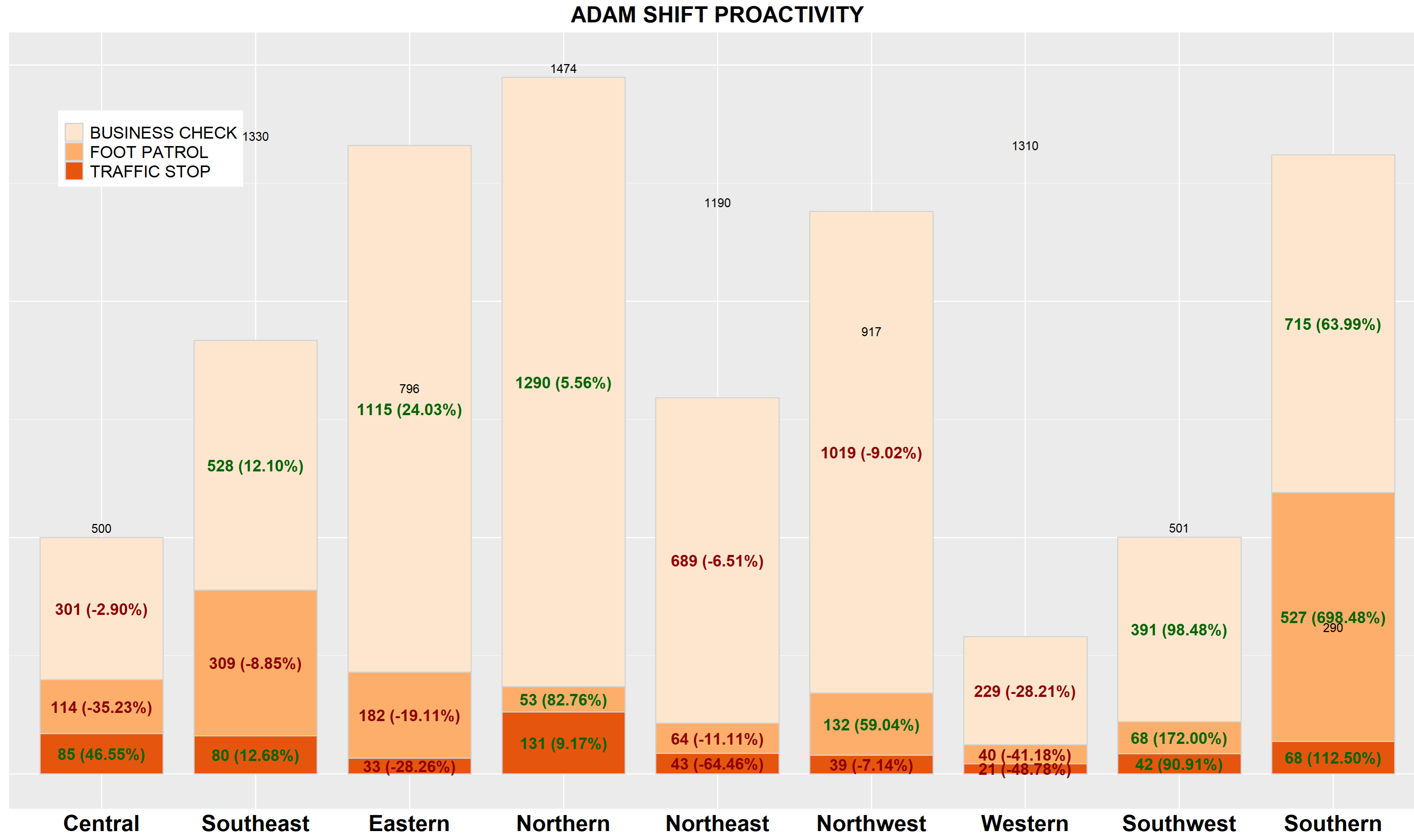
I am attempting to add Column total call out above each column. Here is how my data frame is set up. I will also mention that I am unable to share the complete data but will provide as much as possible. Columns NEW_DIST , CALL_TYPE_OGD (has 3 different chr values), SHIFT (A), Pct_Change, STATUS (Current), COUNT, DIST_COUNT. I currently have the CALL_TYPE_OGD Count and Pct_Change labeled. I want to add the DIST_COUNT above each stacked column. The DIST_COUNT number does not need to be summed. I only need to use one value per NEW_DIST. Not sure if I am making sense.
plot <- ggplot(fd1, aes(x = NEW_DIST, y = COUNT, fill = CALL_TYPE_OGD)) +
geom_bar(position = "stack", stat = "identity", width = 0.8, color = "light gray") +
labs(
title = "ADAM SHIFT PROACTIVITY",
x = "",
y = "",
fill = "CALL_TYPE_OGD"
) +
scale_fill_brewer(type = "seq", palette = 'Oranges') +
# Add data labels using geom_text
geom_text(
aes(label = paste0(COUNT, " (", Pct_Change, "%)")), # Include both raw count and percentage change
position = position_stack(vjust = 0.5),
color = ifelse(fd$Pct_Change >= 0, "darkgreen", "darkred"),
hjust = ifelse(fd$Pct_Change >= 0.5, 0.5, 0.5),
size = 4)
print(plot)
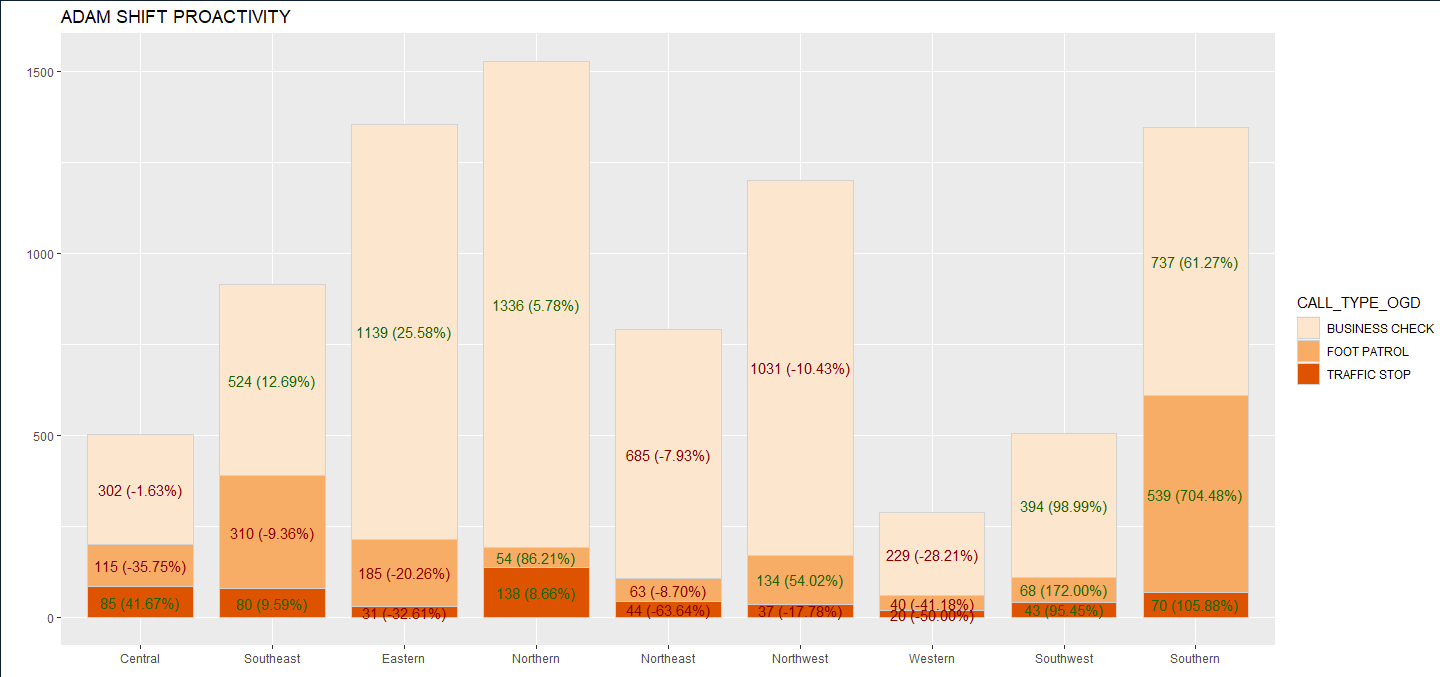
The plot is produced with the code provided above.
Please let me know if I need to provide further clarification or more of the script. I attempted to upload the data frame that was usable but couldn't figure out. Below is the df
"NEW_DIST" "CALL_TYPE_OGD" "SHIFT" "Pct_Change" "STATUS" "COUNT" "DIST_COUNT"
"Central" "BUSINESS CHECK" "A" "-1.63" "CURRENT" 302 502
"Central" "FOOT PATROL" "A" "-35.75" "CURRENT" 115 502
"Central" "TRAFFIC STOP" "A" "41.67" "CURRENT" 85 502
"Eastern" "BUSINESS CHECK" "A" "25.58" "CURRENT" 1139 1355
"Eastern" "FOOT PATROL" "A" "-20.26" "CURRENT" 185 1355
"Eastern" "TRAFFIC STOP" "A" "-32.61" "CURRENT" 31 1355
"Northeast" "BUSINESS CHECK" "A" "-7.93" "CURRENT" 685 792
"Northeast" "FOOT PATROL" "A" "-8.70" "CURRENT" 63 792
"Northeast" "TRAFFIC STOP" "A" "-63.64" "CURRENT" 44 792
"Northern" "BUSINESS CHECK""A" "5.78" "CURRENT" 1336 1528
"Northern" "FOOT PATROL" "A" "86.21" "CURRENT" 54 1528
"Northern" "TRAFFIC STOP" "A" "8.66" "CURRENT" 138 1528
"Northwest" "BUSINESS CHECK""A" "-10.43" "CURRENT" 1031 1202
"Northwest" "FOOT PATROL" "A" "54.02" "CURRENT" 134 1202
"Northwest" "TRAFFIC STOP" "A" "-17.78" "CURRENT" 37 1202
"Southeast" "BUSINESS CHECK""A" "12.69" "CURRENT" 524 914
"Southeast" "FOOT PATROL" "A" "-9.36" "CURRENT" 310 914
"Southeast" "TRAFFIC STOP" "A" "9.59" CURRENT" 80 914
"Southern" "BUSINESS CHECK""A" "61.27" "CURRENT" 737 1346
"Southern" "FOOT PATROL" "A" "704.48" "CURRENT" 539 1346
"Southern" "TRAFFIC STOP" "A" "105.88" "CURRENT" 70 1346
"Southwest" "BUSINESS CHECK""A" "98.99" "CURRENT" 394 505
"Southwest" "FOOT PATROL" "A" "172.00" "CURRENT" 68 505
"Southwest" "TRAFFIC STOP" "A" "95.45" "CURRENT" 43 505
"Western" "BUSINESS CHECK""A" "-28.21" "CURRENT" 229 289
"Western" "FOOT PATROL" "A" "-41.18" "CURRENT" 40 289
"Western" "TRAFFIC STOP" "A" "-50.00" "CURRENT" 20 289
{kind=link}