I wanted to conduct some exploratory analysis of my data. In particular, I require to group my data according to a label (which I have labelled 'distribution'), but I wondered how this was carried out?
For example, would anyone be able to show me would to group observations which have a score that fall into a distribution/label of two?
And thereafter, when it is grouped, would it be possible to explain how it should be stored to conduct some exploratory analysis on it, such as simple descriptive stats etc?
Your help would be very much appreciated. Example data is given:
Thanks @nirgrahamuk . That's a useful link. I appreciate that.
Do you know of a similar example where the data is grouped according to the label, but then you can plot distributions/capture the moments associated with the my 'score' type variable within this label?
EDIT: I think I got it with the psych package. Thanks again for your help.
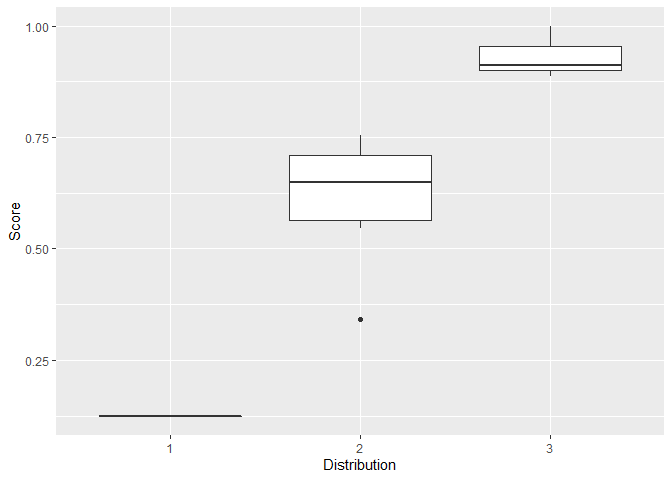
I would add this option, (1) getting summary data for each group and (2) a plot.
Score <- c("0.125", "0.678", "0.999", "0.342", "0.621", "0.912", "0.888", "0.755", "0.722", "0.545")
Distribution <- c("1", "2", "3", "2", "2", "3", "3","2", "2", "2")
df <- data.frame(Score, Distribution)
library(tidyverse)
#> Warning: package 'tidyverse' was built under R version 4.1.2
#> Warning: package 'tibble' was built under R version 4.1.2
#> Warning: package 'readr' was built under R version 4.1.2
df %>%
mutate(Score = as.numeric(Score)) %>% # change from character to numeric
group_by(Distribution) %>% # group by distribution
summarise(mean = mean(Score)) # and give mean for each group
#> # A tibble: 3 x 2
#> Distribution mean
#> <chr> <dbl>
#> 1 1 0.125
#> 2 2 0.610
#> 3 3 0.933
df %>%
mutate(Score = as.numeric(Score)) %>% # change from character to numeric
ggplot() +
geom_boxplot(mapping = aes(x = Distribution, y = Score)) # box plot of score for each distribution