I'm pretty new to (r) and I'm going through the Google Data Analytics Capstone Project and have the following code chunk below. In looking at it, the difference between casual/members is pretty drastic. I'm trying to figure out how to calculate the percentage difference between casual/members by day of the week. I know I need to insert a column ride_length_diff but I'm unsure of the code.
aggregate(bike_rides_v3$ride_length ~ bike_rides_v3$member_casual + bike_rides_v3$day_of_week, FUN = mean)
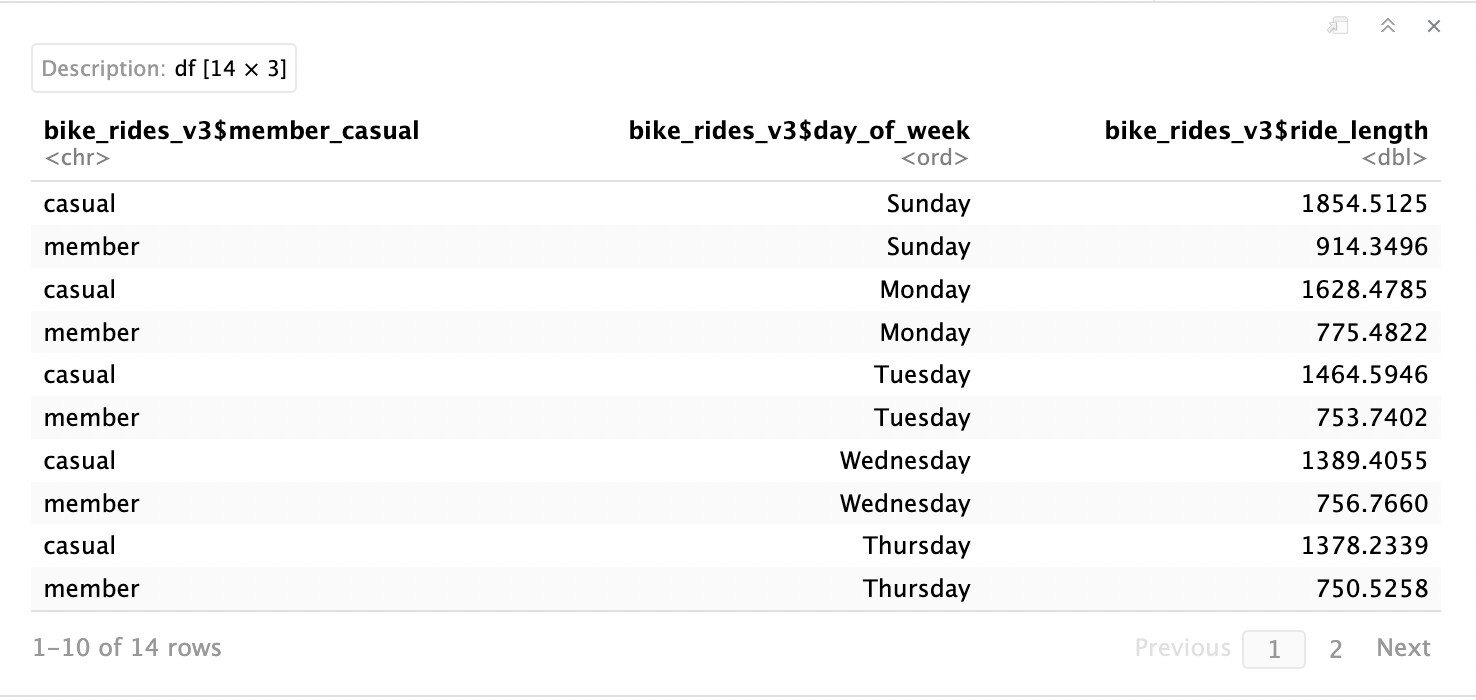
dput(head(bike_rides_v3, 10)[c("day_of_week", "ride_length")])
structure(list(day_of_week = structure(c(7L, 4L, 5L, 5L, 7L,
7L, 2L, 5L, 7L, 1L), levels = c("Sunday", "Monday", "Tuesday",
"Wednesday", "Thursday", "Friday", "Saturday"), class = c("ordered",
"factor")), ride_length = c(625, 244, 80, 702, 43, 3227, 335,
400, 151, 433)), row.names = c(NA, 10L), class = "data.frame")