Hi all, as i have a dataframe
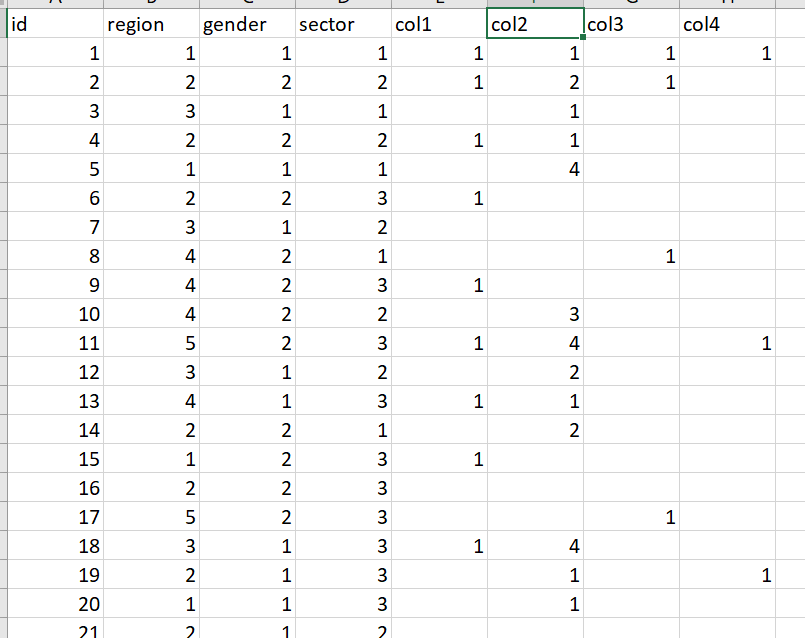
First four columns are Categories,Last four columns are calculated variables.
calculated variables can have values 1,2,3,4 or 1-9
i am trying to create a dynamic function like
function(data,calcuation_var,grouping_var)
also creating dynamic recoding for creating new groups
db$new_var <- recode(db$region,c(1,2)~"A",c(4,5)~"B",c(6,7,8)~"C")
new variable can be A, B, C,.........N
but i am stuck at from where to start, how to start
the required output should be like for Col2
A B C
1 12% 41% 23%
2 7% 10% 6%
3 34% 16% 9%
4 47% 33% 62%
N 53 56 119
% values are (Percentage of occurrence for categories accordingly), N is the Total number of responses.
:Note Please provide a simplest solution as I am new to R , so that i can modify or give theme going forward.
please let me if any more explanation required.