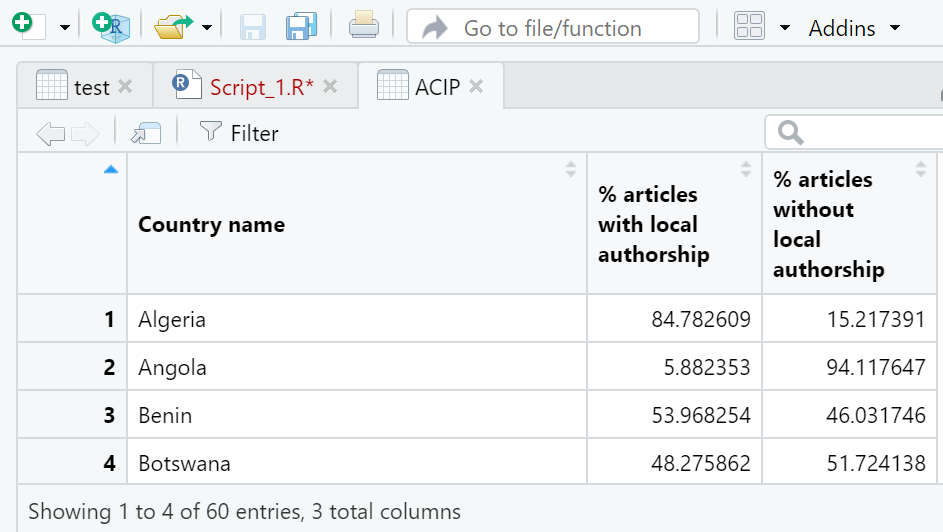
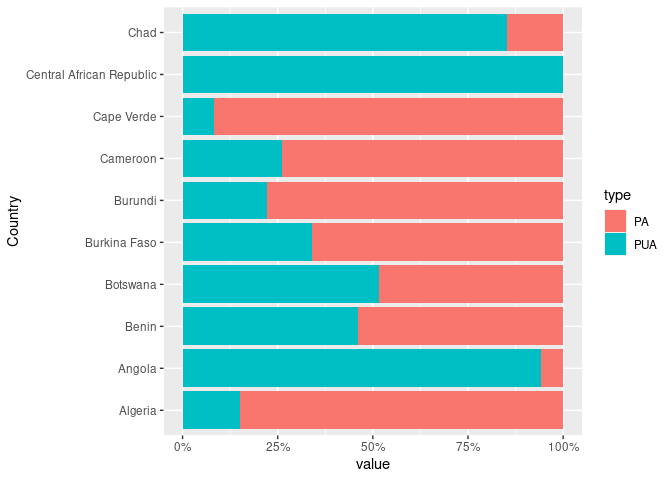
This is not what I had in mind originally but does in look at all useful?
library(tidyverse)
dat1 <- structure(list(Country = c("Algeria", "Angola", "Benin", "Botswana",
"Burkina Faso", "Burundi", "Cameroon", "Cape Verde", "Central African Republic",
"Chad"), Authorship = c(273, 1, 34, 70, 35, 7, 88, 11, 0, 6),
UnAuthorship = c(49, 16, 29, 75, 18, 2, 31, 1, 4, 35), PA = c(84.7826087,
5.882352941, 53.96825397, 48.27586207, 66.03773585, 77.77777778,
73.94957983, 91.66666667, 0, 14.63414634), PUA = c(15.2173913,
94.11764706, 46.03174603, 51.72413793, 33.96226415, 22.22222222,
26.05042017, 8.333333333, 100, 85.36585366)), row.names = c(NA,
-10L), class = c("tbl_df", "tbl", "data.frame"))
dat2 <- dat1 %>%
pivot_longer(c("PA", "PUA"), names_to = "type")
ggplot(data = dat2, aes(x = value, y = Country, colour = type)) + geom_point() +
theme(legend.position = "none") +
facet_grid(. ~ type)