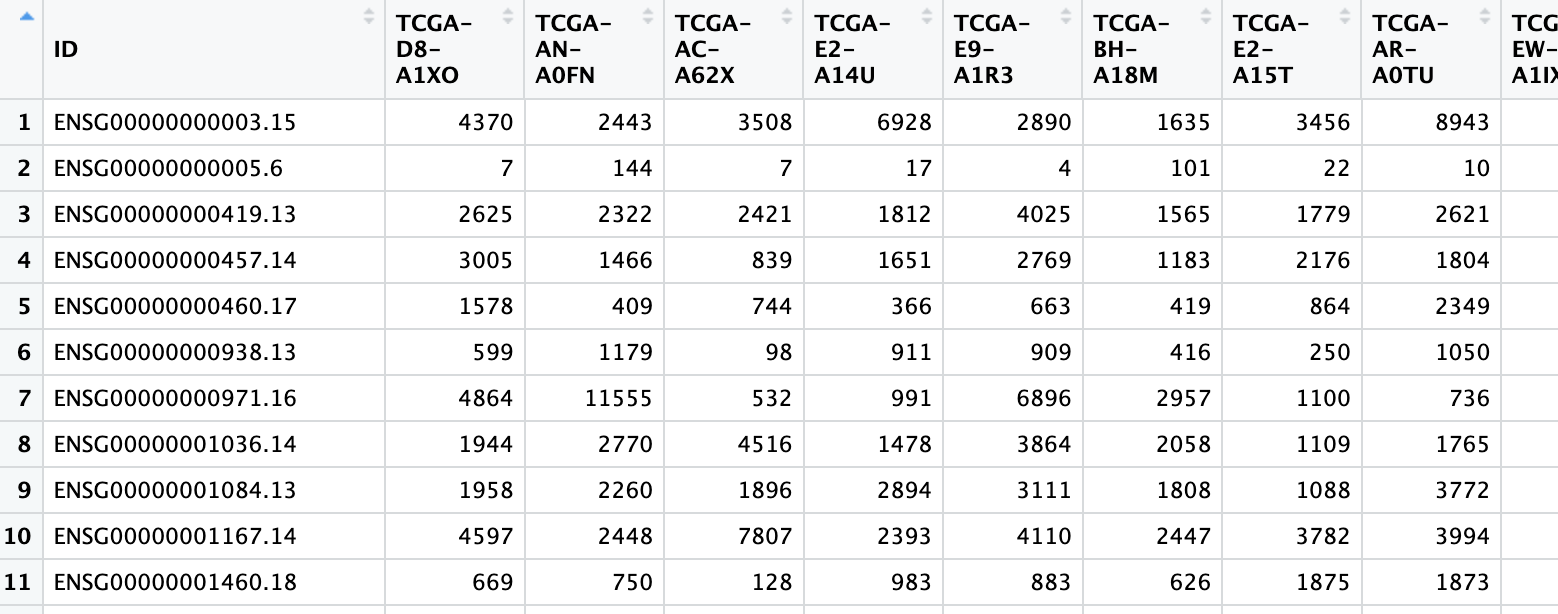
I am fairly new to coding and am having a bit of trouble at the moment with this concept. I currently have 2 df with similar information, except one has a much greater data count. I need to try and create a new df3 which has the information from both df1 and df2. I need to filter the information based on df1 rows and df2 column names, and have them come out in rows. This is currently what I have done and am finding it difficult to continue.
df3 <- for (i in 1:ncol(df2)
if(df1$row == colnames(df2))
)
I'm unsure if this is even the right approach. Apologies if this is the wrong tag.
Sorry, I don't understand your goal. Can you write code to make three small data frames as examples of df1, df2, and df3? You can use the data.frame() function to make them and post that code between lines of three back ticks, like this
```
df1 <- data.frame(A = 1:3, ....)
df2 <- data.frame(....)
df3 <- data.frame)...)
```
I tried to put df1 also but I cannot put 2 screenshots in as a new user. However, df1 has only two columns. Column 1 has 160 rows with the same information that the column names has for df1, and column two of df1 has mutation types.
df1 has roughly 160 entries of patients while df2 has roughly 60,000+ entries. I need to utilise df2 but it has too much information. I only need the same entries from df1. So basically, if df2 = df1 then extract df2 and put into df3. It's important that I keep all of df2 information on the extracted patients. I hope this explains it a little better.
That worked wonderfully thank you very much. I was initially trying to do the same thing with an if and for statement. Trying to compare the two and if true then place it into another df. Your method works perfectly thank you.
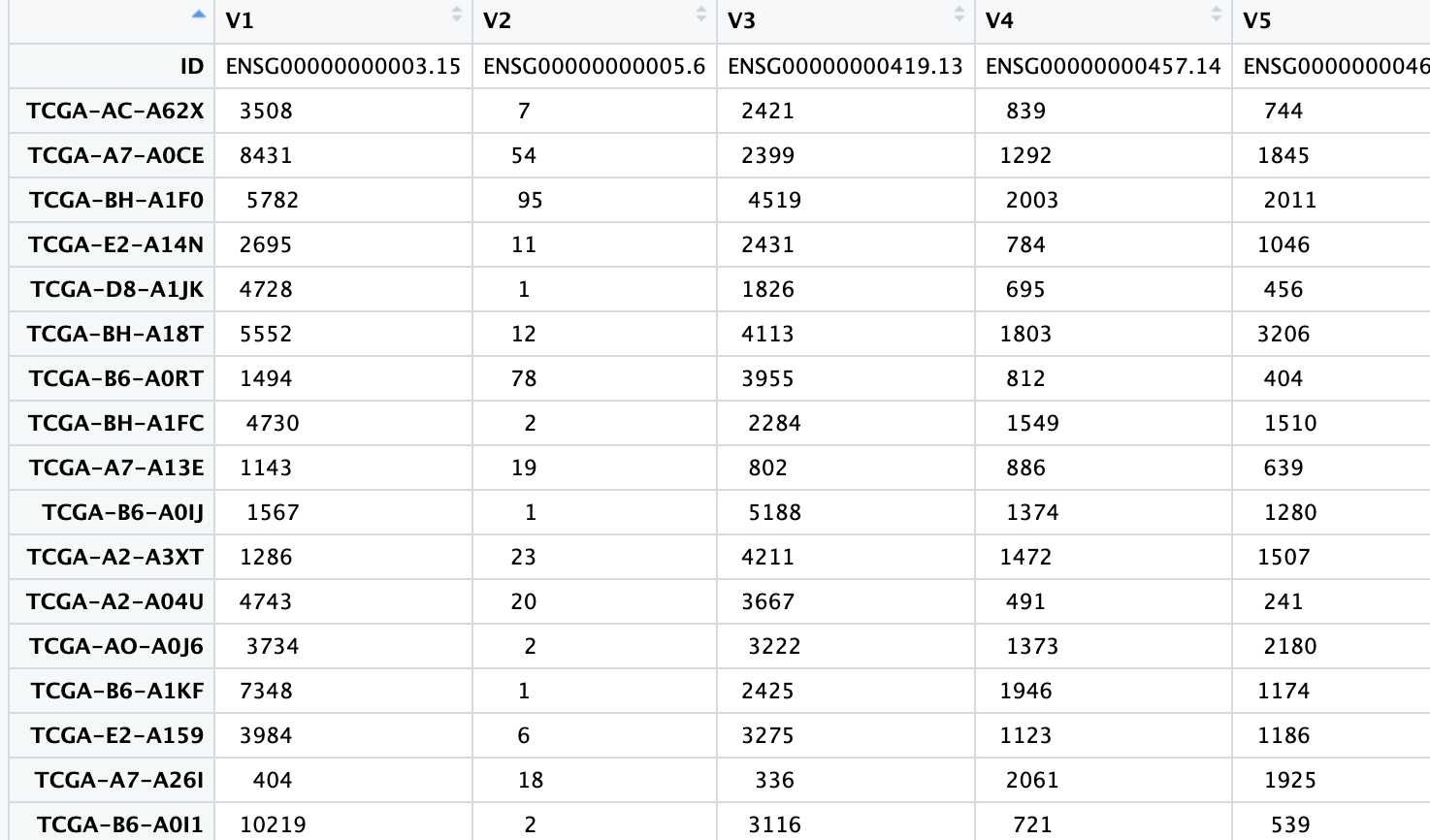
As you can see I rearranged the column to be the rows and vice versa. However I am now trying to remove the V1,V2,V3.... and have the first row be the header row. I should be able to accomplish this on my own. Many thanks again for your help