I am working on a project and I have a dataset named olist_full which contains 112650 observations but I want to focus on 2 specific columns which are order_id and the order_item_id, the order_id which is the order unique identifier (one order, one id) and the order_item_id which indicates the number of items in each order.
it can be that 2 columns have the same orders id cause the same customer placed different orders.
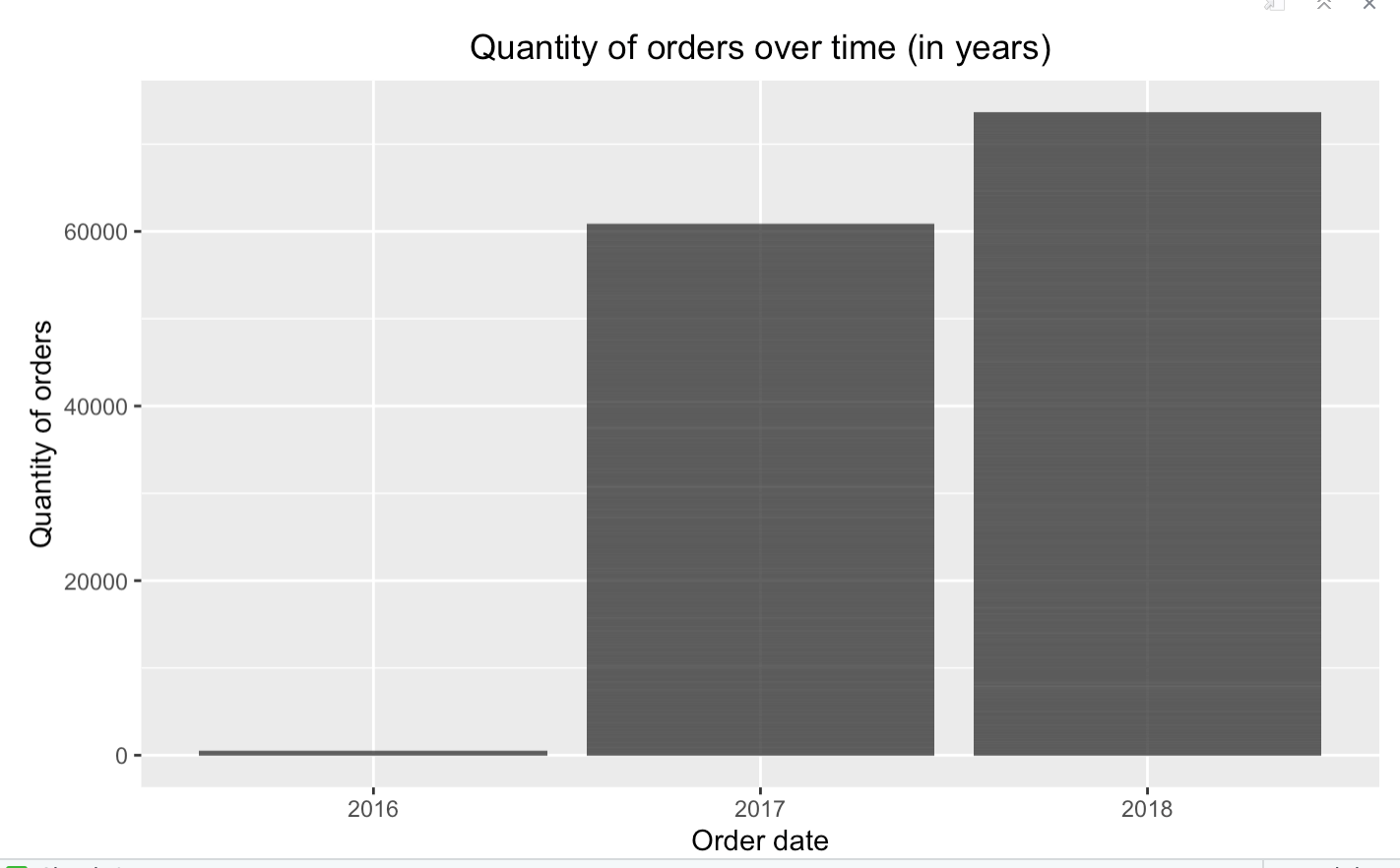
What I am interested in is to build a graph with the quantity of orders in terms of year, months, day of the week....
However I used the order_item_id which biases the results cause it counts orders twice or three times as it does not consider the id but the number of items in the id, which may be more than 1 sometimes.
this is what I obtained by using the following code :
Quantitytimeyear <- ggplot(olist_full, aes(x=year, y=order_item_id)) +
geom_col(aes(x=factor(year), y=order_item_id), stat="identity") + labs(title ="Quantity of orders over time (in years)", y="Quantity of orders", x="Order date") +
theme(
plot.title = element_text(hjust = 0.5),
)
What I want to do is to create graphs which take into account the order id and not the items in the order, so I would have to translate the ids into numbers, how can I do that ?
Hello,
I'm sure you shared this image with the best intentions, but perhaps you didnt realise what it implies.
If someone wished to use example data to test code against, they would type it out from your screenshot...
This is very unlikely to happen, and so it reduces the likelihood you will receive the help you desire.
Therefore please see this guide on how to reprex data. Key to this is use of either datapasta, or dput() to share your data as code