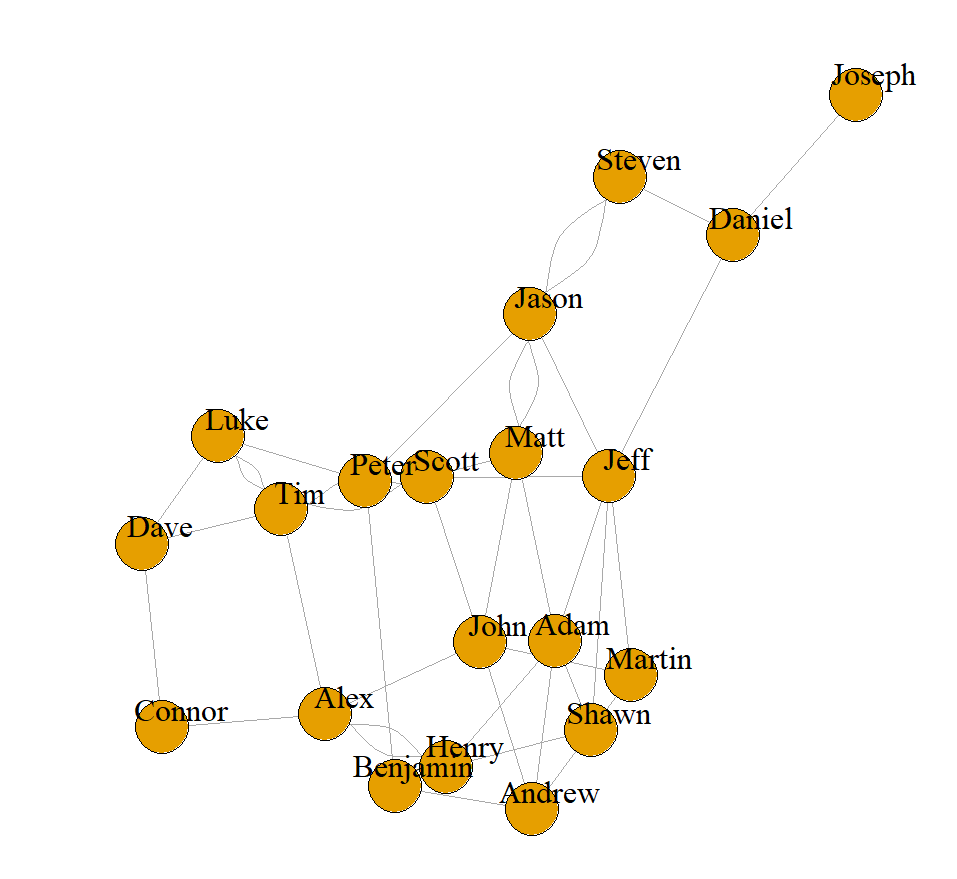
My Question: But from here, I am not sure how to randomly select individual nodes number_of_nodes such that all these nodes are necessarily connected to "John".
For instance - suppose n = 3 and m = 2: I would not want to create a subgraph with "John" , "Jason" and "Steven" - because even though "Jason and Steven" might be within a randomly generated radius, "Jason and Steven" are still not directly connected to "John".
I had to remove that second set.seed() to reproduce your results
I think you mean n = 2 and m = 3 with your definitions?
I have two questions: first, how big is your real problem? Because if you only have 40 edges, you can probably get away with somewhat inefficient solutions, if you have 10k in your real graph, efficiency is a big concern.
Second, what should be the probability of selecting an individual node? One answer could be "each node should have the same probability of being selected in a given subgraph", but that is impossible here: say you want a graph connected to Joseph, every subgraph (of size > 0) would need to contain Daniel, the only connection of Joseph. If you care about a particular probability, you will have to define it precisely.
One solution (which may or may not be what you need depending of your answers above) is:
select all nodes in the neighborhood of John
sample one of them
add this node and every one in the path to John to your subgraph
if the current size of the subgraph is the required size, you're done; if it's bigger than the required size, you cancel the last step and try again with smaller max_degree (or even discard the current subgraph and retry); if it's smaller, you look for a new node and repeat
Here is an example that kind of works in most cases:
try_finding_subgraph <- function(g, x, max_size, max_degree){
#inits
vertices_in_subgraph <- character(0L)
wrong_once <- FALSE
while(TRUE){
new_node <- sample(ego(g, max_degree, x)[[1]], 1)
new_vertices_in_subgraph <- shortest_paths(g, from = names(new_node), to = x)$vpath[[1]] |>
names()
vertices_in_subgraph_ext <- unique(c(vertices_in_subgraph, new_vertices_in_subgraph))
if(length(vertices_in_subgraph_ext) == max_size){
# done
return(induced_subgraph(g, vertices_in_subgraph_ext))
} else if(length(vertices_in_subgraph_ext) < max_size){
# need more nodes
vertices_in_subgraph <- vertices_in_subgraph_ext
} else if(length(vertices_in_subgraph_ext) > max_size){
# we went too far, discard vertices_in_subgraph_ext and try again
# if we're already trying again, we're in the wrong path, we give up
if(wrong_once){
return(make_empty_graph())
}
wrong_once <- TRUE
}
}
}
try_finding_subgraph(g, "Joseph", 3, 2)
#> IGRAPH 7e18d25 UN-- 3 2 --
#> + attr: name (v/c)
#> + edges from 7e18d25 (vertex names):
#> [1] Jeff --Daniel Daniel--Joseph
Noting that this is pretty bad: if I don't seem to find the right graph I just give up and return an empty one. If you're not lazy as me you can probably do better. The point of this code is really just to give you something that works, not to fully solve the problem.
Actually if you truly want to fully solve the problem, you probably would want to list all possible paths within max_degree of the node of interest, then try making all combinations of such paths, and finally select the ones that satisfy the condition on max_size. Obviously, you'll run into efficiency problems if you have a big graph.
Here is a tentative (not extensively tested):
x <- "Joseph"
max_degree <- 2
max_size <- 3
# find all nodes that satisfy degree requirement
all_nodes_in_range <- names(ego(g, max_degree, x)[[1]])
# reconstruct all paths that are made from those nodes
all_paths_in_range <- lapply(all_nodes_in_range,
\(.from) shortest_paths(g, from = .from, to = x)$vpath[[1]] |>
names())
# given a combination of two or more paths, extract their nodes
measure_paths <- function(combination_of_paths){
cur_path <- unique(unlist(combination_of_paths))
tibble::tibble(nb_nodes = length(cur_path),
node_names = list(cur_path))
}
# make all combinations of paths, combining any number of paths
all_paths_combinations_measures <- lapply(seq_len(max_size),
\(.nb_paths) combn(all_paths_in_range, .nb_paths, simplify = FALSE) |>
lapply(measure_paths) |>
purrr::list_rbind()) |>
purrr::list_rbind() |>
# sort each node list to eliminate duplicates
dplyr::mutate(node_names = lapply(node_names, sort)) |>
unique()
all_paths_combinations_measures$node_names[all_paths_combinations_measures$nb_nodes == max_size] |>
lapply(\(.x) induced_subgraph(g, .x))
#> [[1]]
#> IGRAPH f95aa7c UN-- 3 2 --
#> + attr: name (v/c)
#> + edges from f95aa7c (vertex names):
#> [1] Steven--Daniel Daniel--Joseph
#>
#> [[2]]
#> IGRAPH f95aeaf UN-- 3 2 --
#> + attr: name (v/c)
#> + edges from f95aeaf (vertex names):
#> [1] Jeff --Daniel Daniel--Joseph
I didn't write it as a function, but that would be easy to add. Indeed (if I didn't make a mistake), it should find all the subgraphs satisfying those conditions.
Then one easy way is, after generating all corresponding subgraphs, just select one randomly (with sample()). The advantage of this approach is that you can see how many there are, and detect for example the cases where there is no answer (e.g. you're looking at a disconnected component of a graph etc).
If the problem is the size of the graph, making it unpractical to compute all possible subgraphs, then the function try_finding_subgraph () does that, trying to build a single such subgraph. It needs a lot of polishing to be good, but you might get something good enough for your use.
Then again, the definition of "truly random" depends on the context, if you want to guarantee equal, unbiased, probabilities of a set of nodes or paths then you might need a different approach.