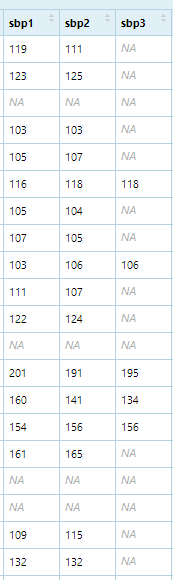
In a dataset of blood pressure readings, I'm trying to create a new average variable for blood pressure that takes two out of three based on the best readings. If a third reading is present, I take that with the first and average it. If not, its an average of the first and second. The variables are continous. This is the code i'm using, but I get a really long error message:
Code in R:
CARRS$sbp_avg = NA
CARRS[which(is.na(CARRS$sbp3)==F),]$sbp_avg = (CARRS[which(is.na(CARRS$sbp3)==F),]$sbp2+
CARRS[which(is.na(CARRS$sbp3)==F),]$sbp3)/2
CARRS[which(is.na(CARRS$sbp3)==T),]$sbp_avg = (CARRS[which(is.na(CARRS$sbp3)==T),]$sbp2+
CARRS[which(is.na(CARRS$sbp3)==T),]$sbp1)/2
Error message:
Coerced double RHS to logical to match the type of the target column (column 69 named 'sbp_avg'). If the target column's type logical is correct, it's best for efficiency to avoid the coercion and create the RHS as type logical. To achieve that consider R's type postfix: typeof(0L) vs typeof(0), and typeof(NA) vs typeof(NA_integer_) vs typeof(NA_real_). You can wrap the RHS with as.logical() to avoid this warning, but that will still perform the coercion. If the target column's type is not correct, it's best to revisit where the DT was created and fix the column type there; e.g., by using colClasses= in fread(). Otherwise, you can change the column type now by plonking a new column (of the desired type) over the top of it; e.g. DT[, sbp_avg :=as.double( sbp_avg )]. If the RHS of := has nrow(DT) elements then the assignment is called a column plonk and is the way to change a column's type. Column types can be observed with sapply(DT,typeof).Coerced double RHS to logical to match the type of the target column (column 69 named 'sbp_avg'). If the target column's type logical is correct, it's best for efficiency to avoid the coercion and create the RHS as type logical. To achieve that consider R's type postfix: typeof(0L) vs typeof(0), and typeof(NA) vs typeof(NA_integer_) vs typeof(NA_real_). You can wrap the RHS with as.logical() to avoid this warning, but that will still perform the coercion. If the target column's type is not correct, it's best to revisit where the DT was created and fix the column type there; e.g., by using colClasses= in fread(). Otherwise, you can change the column type now by plonking a new column (of the desired type) over the top of it; e.g. DT[, sbp_avg :=as.double( sbp_avg )]. If the RHS of := has nrow(DT) elements then the assignment is called a column plonk and is the way to change a column's type. Column types can be observed with sapply(DT,typeof).