For context, I want to create a barplot showing the relationship between respondents' gender and their political identity (left or right only). Something like:
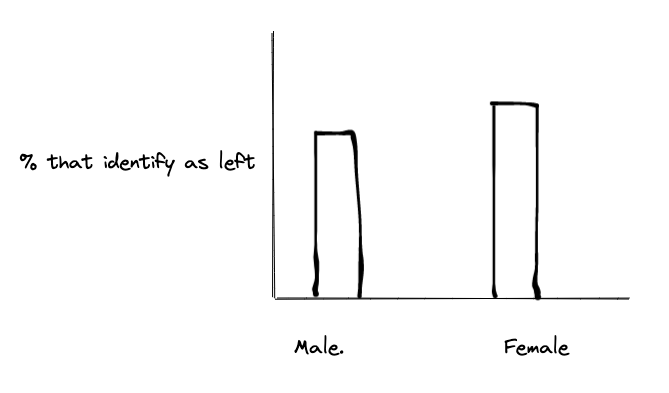
This is what I've done so far:
# create dataframe with only those respondents are either left or right and who have strong partisan identity, create new column to label them as left (1) or right (2)
strongId_frame <- data.frame(bes_strongId) # make dataframe out of only those who say they have strong partisan identity
strongId_frame$generalElectionVote <- as.character(strongId_frame$generalElectionVote) # change variable showing how respondents voted into character data type (was originally factor variable)
strongestId_frame <- strongId_frame[complete.cases(strongId_frame$generalElectionVote), ] #remove the rows with missing values in columns which record no response for how someone voted
partisan_identity <- ifelse(strongId_frame$generalElectionVote %in% c("Labour", "Green Party", "Liberal Democrat"), 1,
ifelse(strongId_frame$generalElectionVote %in% c("Conservative"), 2, NA)) #make new column where all left-voting respondents become 1 and right-voting respondents 2
# what % of women are left identifying?
women_w_strongId <- strongestId_frame[strongestId_frame$gender == "Female",]
women_w_strongId %>%
count(strongestId_frame$partisan_identity == 1) %>%
mutate(percent = n/sum(n)*100)
Possible problem #1 - Maybe the partisan_identity
I also tried:
partisan_identity <- ifelse(strongId_frame$generalElectionVote %in% c(2, 3, 7), 1,
ifelse(strongId_frame$generalElectionVote %in% c(1), 2, NA))
partisan_identity <- ifelse(match(strongId_frame$generalElectionVote, c("Labour", "Green Party", "Liberal Democrat")) > 0, 1,
ifelse(match(strongId_frame$generalElectionVote, c("Conservative")) > 0, 2, NA))
I can't find partisan_identity listed at end of colnames(strongestId_frame), or names(strongestId_frame)
I get the following using summary(strongestId_frame$partisan_identity):
Length Class Mode
0 NULL NULL
Possible problem #2 - Maybe the problem is to do with missing data
??
I'm pretty sure all the column and value names are right.