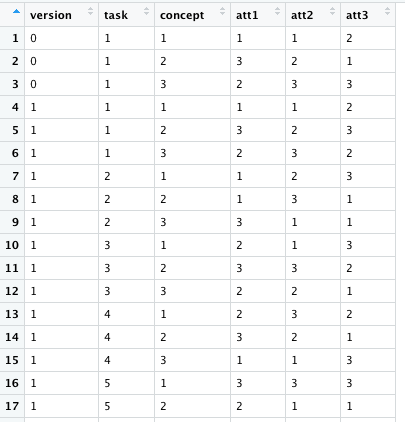
OK, that helped. I think you want something like this. Here I've prefixed the resulting columns with t and c (for task and concept respectively) and their values from the original data frame.
library(tidyverse)
data <- tribble(~ version, ~ task, ~ concept, ~ attr1, ~ attr2, ~ attr3,
0, 1, 1, 1, 1, 2,
0, 1, 2, 3, 2, 1,
0, 1, 3, 2, 3, 3,
1, 1, 1, 1, 1, 2,
1, 1, 2, 3, 2, 3,
1, 1, 3, 2, 3, 2)
data %>%
pivot_longer(cols = c(attr1, attr2, attr3)) %>%
mutate(new_name = str_c("t", task, "_c", concept, "_", name)) %>%
pivot_wider(id_cols = version, names_from = new_name, values_from = value)
#> # A tibble: 2 x 10
#> version t1_c1_attr1 t1_c1_attr2 t1_c1_attr3 t1_c2_attr1 t1_c2_attr2
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0 1 1 2 3 2
#> 2 1 1 1 2 3 2
#> # ... with 4 more variables: t1_c2_attr3 <dbl>, t1_c3_attr1 <dbl>,
#> # t1_c3_attr2 <dbl>, t1_c3_attr3 <dbl>
Created on 2020-05-05 by the reprex package (v0.3.0)