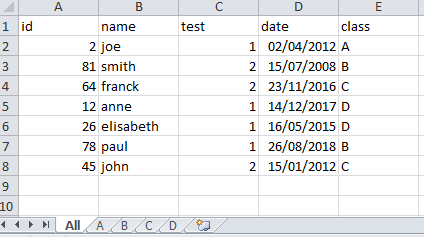
Hello! So I have a dataframe and at the end a column who classify my row and I want to export that in xlsxand obtain a file with one tab for each of my classification level. For example my level are A,B,C,D and I want in my xlsx tabs with the rows corresponding to A, B,C,D :
Hello,
I'm sure you shared this image with the best intentions, but perhaps you didnt realise what it implies.
If someone wished to use example data to test code against, they would type it out from your screenshot...
This is very unlikely to happen, and so it reduces the likelihood you will receive the help you desire.
Therefore please see this guide on how to reprex data. Key to this is use of either datapasta, or dput() to share your data as code
Writexl will write to separate tabs in the workbook if the data.frames are split into a named list
library("tidyverse")
library("lubridate")
#>
#> Attaching package: 'lubridate'
#> The following objects are masked from 'package:base':
#>
#> date, intersect, setdiff, union
library("writexl")
# Using a toy data set
set.seed(123)
dat <- tibble(
id = rpois(7, 15),
name = letters[1:7],
test = sample(1:2, size = 7, replace = TRUE),
date = dmy(c("02/04/2012", "15/07/2008", "23/11/2016", "14/12/2017",
"16/05/2015", "26/08/2018", "15/01/2012")),
class = sample(LETTERS[1:4], size = 7, replace = TRUE)
)
dat_split <- dat %>%
split(dat, f = dat$class)
dat_split
#> $A
#> # A tibble: 2 × 5
#> id name test date class
#> <int> <chr> <int> <date> <chr>
#> 1 12 a 1 2012-04-02 A
#> 2 10 g 1 2012-01-15 A
#>
#> $B
#> # A tibble: 2 × 5
#> id name test date class
#> <int> <chr> <int> <date> <chr>
#> 1 15 d 1 2017-12-14 B
#> 2 16 f 1 2018-08-26 B
#>
#> $C
#> # A tibble: 2 × 5
#> id name test date class
#> <int> <chr> <int> <date> <chr>
#> 1 19 b 1 2008-07-15 C
#> 2 21 e 2 2015-05-16 C
#>
#> $D
#> # A tibble: 1 × 5
#> id name test date class
#> <int> <chr> <int> <date> <chr>
#> 1 8 c 1 2016-11-23 D
write_xlsx(dat_split, path = "~/Desktop/dat.xlsx",
format_headers = FALSE)