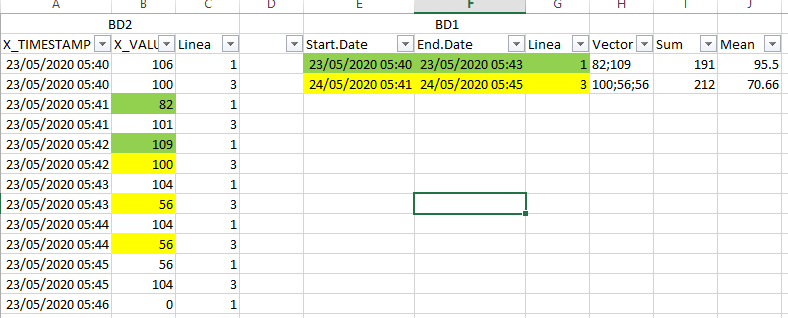
I have a problem a little complicate. I have two database BD and BD2 . For every row in BD I want to search in entire BD2 and obtain some info: Sum, Mean, Sd etc. With Sum I succeeded to make it work, but for Mean, Sd, Median I want to obtain the vector and after that apply these functions.
To be clearer, here is the code. For sum it worked. But I want now to save in a vector the values that met the conditions and after calculate Mean , Sd , Median . I tried to make the vector out of the base BD but nothing work or is something trickie and I can't figure it out.
for (i in 1:dim(BD)[1])
{
for (j in 1:dim(BD2)[1])
{
if((BD$Start.Date[i]<BD2$X_TIMESTAMP[j]) && (BD2$X_TIMESTAMP[j]<BD$End.Date[i]) && (BD$Linea[i]==BD2$Linea[j]))
{
vl = BD2$X_VALUE[j]
BD$vec[i] = paste(BD$vec[i],vl,sep="")
#vect = as.numeric(BD$vec[i])
BD$Sum[i] = BD$Sum[i]+ BD2$X_VALUE[j]
#BD$Average[i] = mean(vect)
}
}
}
I tried to create vec before the for sentence. But still it doesn't work. The error is always the same: Error in $<-.data.frame(*tmp*, "vec", value = list(NULL, NULL, NULL, : replacement has 47 rows, data has 530
EDIT: I added a photo with details. In fact, I don't necessarily want to retain the vector. I jus want to be able to calculate Mean, Sd etc.
I think there are indeed some more elegant solutions to this issue, but you'll need to provide me a bit extra info. Can you show me a sample of both databases and tell me which columns are linked (foreign keys) and which values need to be calculated (i.e. provide an example of input and output).
To help us understand, read the reprex guide. A reprex consists of the minimal code and data needed to recreate the issue/question you're having. You can find instructions how to build and share one here:
Thank you very much. I succeeded to fix the for sentence but it takes a lot to run. I have in BD = 530 rows and BD2 = 700k. I tried your code, but I don't know why when I make group by it reduce my database at only 13 observation, even if the start.date it doesn't have a value repeated.
13L. Smth happened when I apllied dmy_hm(BD$Start.Date). In my original code I have BD$Start.Date = strptime(as.character(BD$Start.Date),format="%d.%m.%Y %H:%M") because in the original Database the date are like this: 14.05.2020 21:12. I tried with strptime but I have an error when I try to run fuzzy_inner_join. I think it's better to create a unique key in BD to be sure that nothing will reduce the size. Did you ever create smth like this? I don't know, a random no.. Thank you
Your code using strptime() should work fine. Use that if you prefer it over dmy_hm().
Is it possible that there really are only 13 cases where Start.Date, End.Date and Linea all meet the requirements? Any rows in BD that do not have matching data in BD2 will be dropped from BDjoin. Note that the match conditions are < and > not <= and >=.
Do you expect most rows in BD to have matching data in BD2? Can you find any rows in BD that do have matches in BD2 but do not appear in BDstats?
I think you are right. A last question, if you know please: I have for other database the conditions: Start.Data+2 min < X_TIMESTAMP < End.Date - 10 min. Do you know how to write this in match_fun in the fuzzy_inner_join sentence? Thank you.
I just created others 2 columns, but your solution seems to be good also. Unfortunately, when I try to run fuzzy_inner_join with my original database (530 BD and 120k BD2) I get this error: Error: std::bad_alloc. I closed the R Session and open again, but still doesn't work.