Hello! My data looks like below (it is partially cleaned output from using udpipe). There is a token for each row, drawn from the sentence held in the column 'sentence', with its position in the sentence held in the column 'token_id'. The position of the sentence in each document is held in 'sentence_id', and the number of the document in the overall corpus is held in 'doc_id'. The 'head_token_id' hold the 'token_id' for the word which the 'token' depends on. For example, in 'The red dog barked', the row with 'red' as the token would have a token_id of 2, but a head_token_id of 2, since red is the adjective for 'dog' in that sentence. 'dep_rel' gives the exact relationship (so the row with 'red' would be 'adj' for adjective).
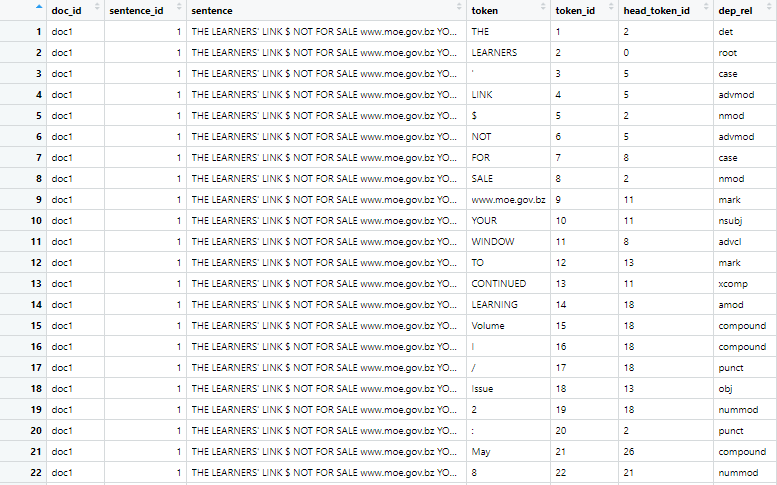
I would like to create a new column, called 'head_token', which contains the value in the column 'token' - but from the row described by 'head_token_id' (as well as doc_id and sentence_id). So in the 'the red dog barked' example, the row with the token 'red' should have a 'head_token' value of 'head'. As an added complication, head_token_id = 0 means that the token is the root of the sentence, so 'head_token' should be NA. Hope that makes sense and appreciate any ideas!
Example data:
data <- structure(list(doc_id = c("doc1", "doc1", "doc1", "doc1", "doc1",
"doc1", "doc1", "doc1", "doc1", "doc1"), sentence_id = c(1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L), sentence = c("THE LEARNERS' LINK $ NOT FOR SALE www.moe.gov.bz YOUR WINDOW TO CONTINUED LEARNING Volume I/Issue 2: May 8, 2020 Learning Activity",
"THE LEARNERS' LINK $ NOT FOR SALE www.moe.gov.bz YOUR WINDOW TO CONTINUED LEARNING Volume I/Issue 2: May 8, 2020 Learning Activity",
"THE LEARNERS' LINK $ NOT FOR SALE www.moe.gov.bz YOUR WINDOW TO CONTINUED LEARNING Volume I/Issue 2: May 8, 2020 Learning Activity",
"THE LEARNERS' LINK $ NOT FOR SALE www.moe.gov.bz YOUR WINDOW TO CONTINUED LEARNING Volume I/Issue 2: May 8, 2020 Learning Activity",
"THE LEARNERS' LINK $ NOT FOR SALE www.moe.gov.bz YOUR WINDOW TO CONTINUED LEARNING Volume I/Issue 2: May 8, 2020 Learning Activity",
"THE LEARNERS' LINK $ NOT FOR SALE www.moe.gov.bz YOUR WINDOW TO CONTINUED LEARNING Volume I/Issue 2: May 8, 2020 Learning Activity",
"THE LEARNERS' LINK $ NOT FOR SALE www.moe.gov.bz YOUR WINDOW TO CONTINUED LEARNING Volume I/Issue 2: May 8, 2020 Learning Activity",
"THE LEARNERS' LINK $ NOT FOR SALE www.moe.gov.bz YOUR WINDOW TO CONTINUED LEARNING Volume I/Issue 2: May 8, 2020 Learning Activity",
"THE LEARNERS' LINK $ NOT FOR SALE www.moe.gov.bz YOUR WINDOW TO CONTINUED LEARNING Volume I/Issue 2: May 8, 2020 Learning Activity",
"THE LEARNERS' LINK $ NOT FOR SALE www.moe.gov.bz YOUR WINDOW TO CONTINUED LEARNING Volume I/Issue 2: May 8, 2020 Learning Activity"
), token = c("THE", "LEARNERS", "'", "LINK", "$", "NOT", "FOR",
"SALE", "www.moe.gov.bz", "YOUR"), token_id = c("1", "2", "3",
"4", "5", "6", "7", "8", "9", "10"), head_token_id = c("2", "0",
"5", "5", "2", "5", "8", "2", "11", "11"), dep_rel = c("det",
"root", "case", "advmod", "nmod", "advmod", "case", "nmod", "mark",
"nsubj")), row.names = c(NA, 10L), class = "data.frame")