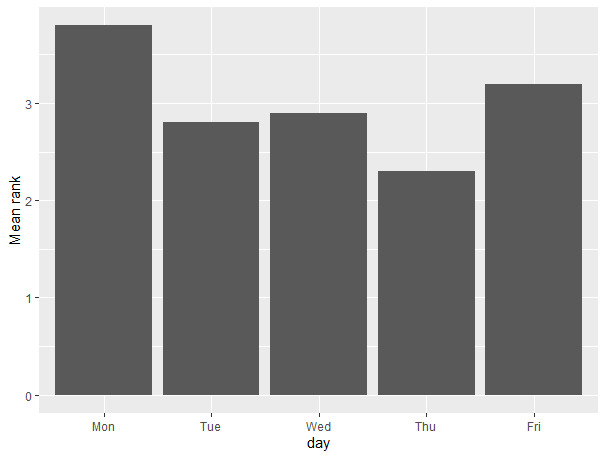I'm clearly missing something. I have test data to share. Question 5 of survey simply asks what days would you like to work from home, select all that apply (M-F and No Preference). If I did this correctly, you will see six people who have done the pre-test. Because the test data was so small, I split it up prior to bringing it into R (I suspect no more than 200 people will be taking this).
As you can see, I have NA's as some people will only work from home x2 a week, others like x3.
The goal is to do what you did, plot a bar chart and see the what people think. Perhaps this is what you were looking for? Thanks again. Appreciate any info.
Testy
A tibble: 6 x 4
ID Q5.1 Q5.2 Q5.3
1 14 Wednesday Thursday NA
2 15 Monday Thursday Friday
3 16 Thursday Friday NA
4 17 Tuesday Thursday NA
5 18 Tuesday Wednesday Thursday
6 19 Wednesday Friday NA
dput(Testy, file = "",
structure(list(ID = c(14, 15, 16, 17, 18, 19), Q5.1 = c("Wednesday",
"Monday", "Thursday", "Tuesday", "Tuesday", "Wednesday"), Q5.2 = c("Thursday",
"Thursday", "Friday", "Thursday", "Wednesday", "Friday"), Q5.3 = c(NA,
"Friday", NA, NA, "Thursday", NA)), class = c("spec_tbl_df",
"tbl_df", "tbl", "data.frame"), row.names = c(NA, -6L), spec = structure(list(
cols = list(ID = structure(list(), class = c("collector_double",
"collector")), Q5.1 = structure(list(), class = c("collector_character",
"collector")), Q5.2 = structure(list(), class = c("collector_character",
"collector")), Q5.3 = structure(list(), class = c("collector_character",
"collector"))), default = structure(list(), class = c("collector_guess",
"collector")), skip = 1), class = "col_spec"))