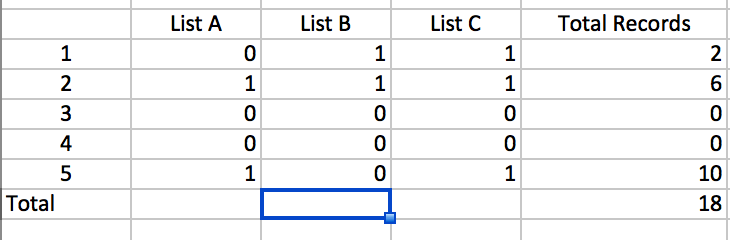
I'm trying to create counts by channel. So I can figure out how many purchases an individual made by channel.
df <- tibble(
memberid = c("123","123","123", "123", "123","123","123","234","345","345",
"456", "456","456", "456","456", "456","456","456"),
channel = c("A","A","A","A","B","A","B","C","C","C","C","A","B","C","C","C","C","A"),
master_subordinant = c("M","S","S","S","S","S","S","M","M","S","M","S","S","S","S","S","S","S")
)
print(df)
# how do I create counts by channel that have duplicate records by memberid?
# for example channel = "A": How many records in that channel have 1 unique record,
# 2 duplicate records,
# 3 duplicate records, and 4+ duplicate record.
# same for channels B and C.