Hi,
First of all, I indeed forgot to assign the result to a variable like @Yarnabrina suggested, so thank you to him for noticing.
The code should indeed be very fast and efficient, because I tested it with 5 million rows and the result was almost instantaneous
library(tidyr)
library(dplyr)
nRows = 5000000
myData = data.frame(Policy = sample(1:50, nRows, replace = T),
Main = sample(c("A", "E"), nRows, replace = T, prob = c(0.9,0.1)))
myData = myData %>% left_join(
myData %>% filter(Main == "A") %>%
group_by(Policy) %>% summarise(output = n()),
by = c("Policy" = "Policy")) %>%
replace_na(list(output = 0))
Regarding your new question: it's best to start them in a new topic next time as this will be easier for other folk to find it back when looking for help (the title refers to the first issue).
To answer it anyway: it's an even easier implementation given you can just use the group_by and mutate:
myData = data.frame(Policy = c(1,2,2,2,4,3,4,8),
Premium = c(5,6,8,7,9,2,1,4))
myData = myData %>% group_by(Policy) %>% mutate(output = sum(Premium))
Policy Premium output
<dbl> <dbl> <dbl>
1 1 5 5
2 2 6 21
3 2 8 21
4 2 7 21
5 4 9 10
6 3 2 2
7 4 1 10
8 8 4 4
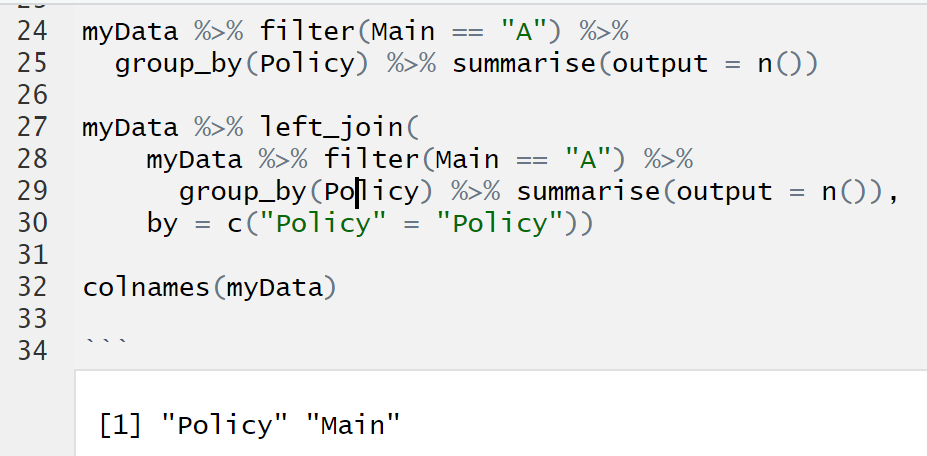
While writing this, I realised that I could write the original code the same way and make it even simpler (though maybe slightly less fast, though still within several seconds on 5m rows)
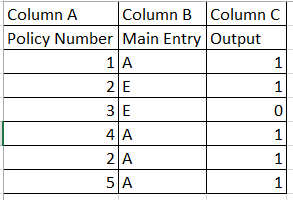
myData = data.frame(Policy = c(1:3, 4,2,5), Main = c("A", "E","E", "A", "A", "A"))
myData = myData %>% group_by(Policy) %>% mutate(output = sum(Main == "A"))
Policy Main output
<dbl> <fct> <int>
1 1 A 1
2 2 E 1
3 3 E 0
4 4 A 1
5 2 A 1
6 5 A 1
These magical functions are all part of the Tidyverse. I suggest you read more about those and you'll be able to replicate any Excel function faster and better 
PJ