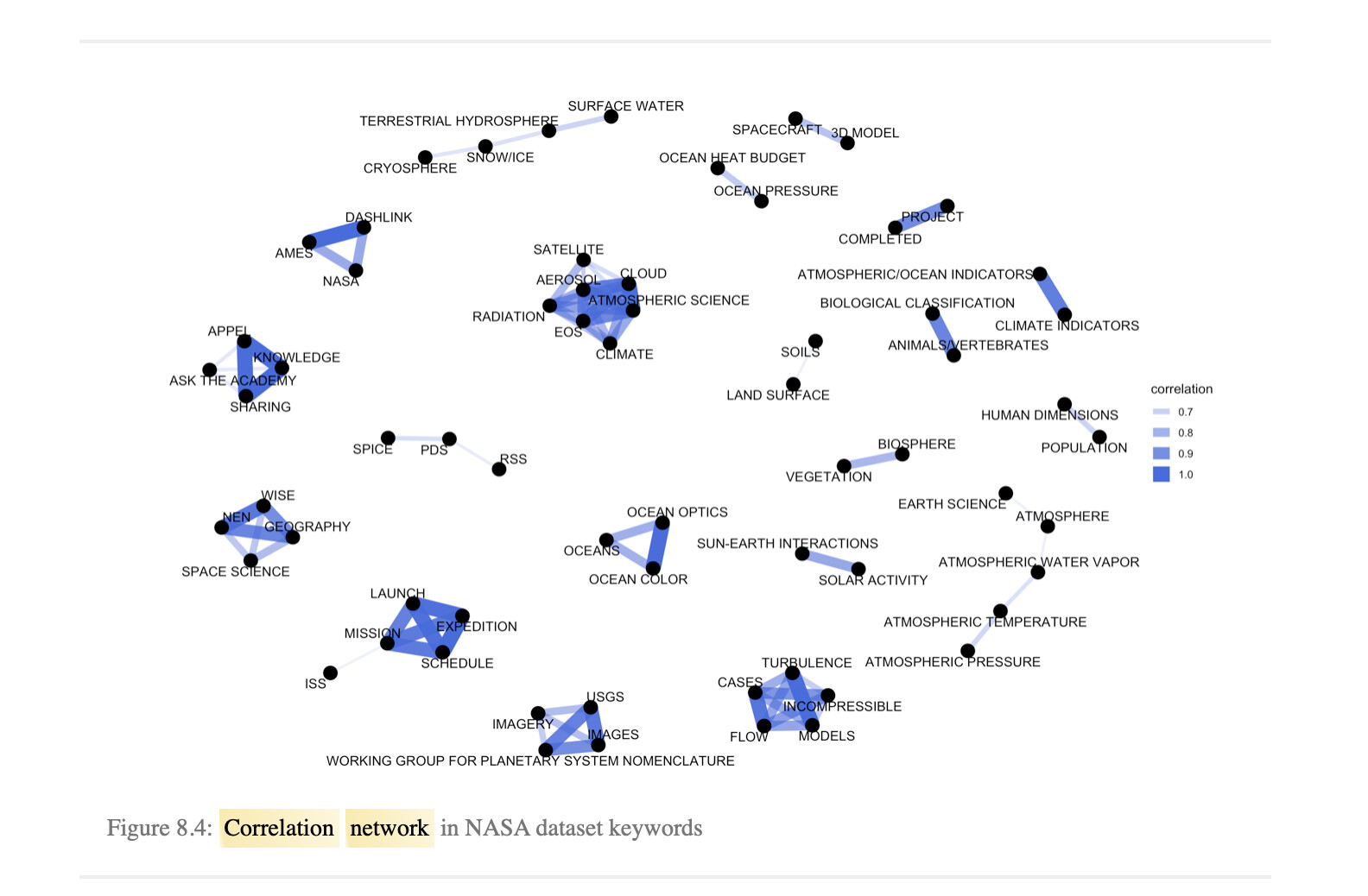
I'm using a tutorial (https://www.tidytextmining.com/nasa.html?q=correlation ne#networks-of-keywords) to learn about tidy text mining. I am hoping someone might be able to help with two questions:
- in this tutorial, the correlation used to make the graph is 0.15. Is this best practice? I can't find any literature to help choose a cut off.
- In the graph attached from the tutorial, how are clusters centrality chosen? Are more important words closer to the centre?
Thanks very much