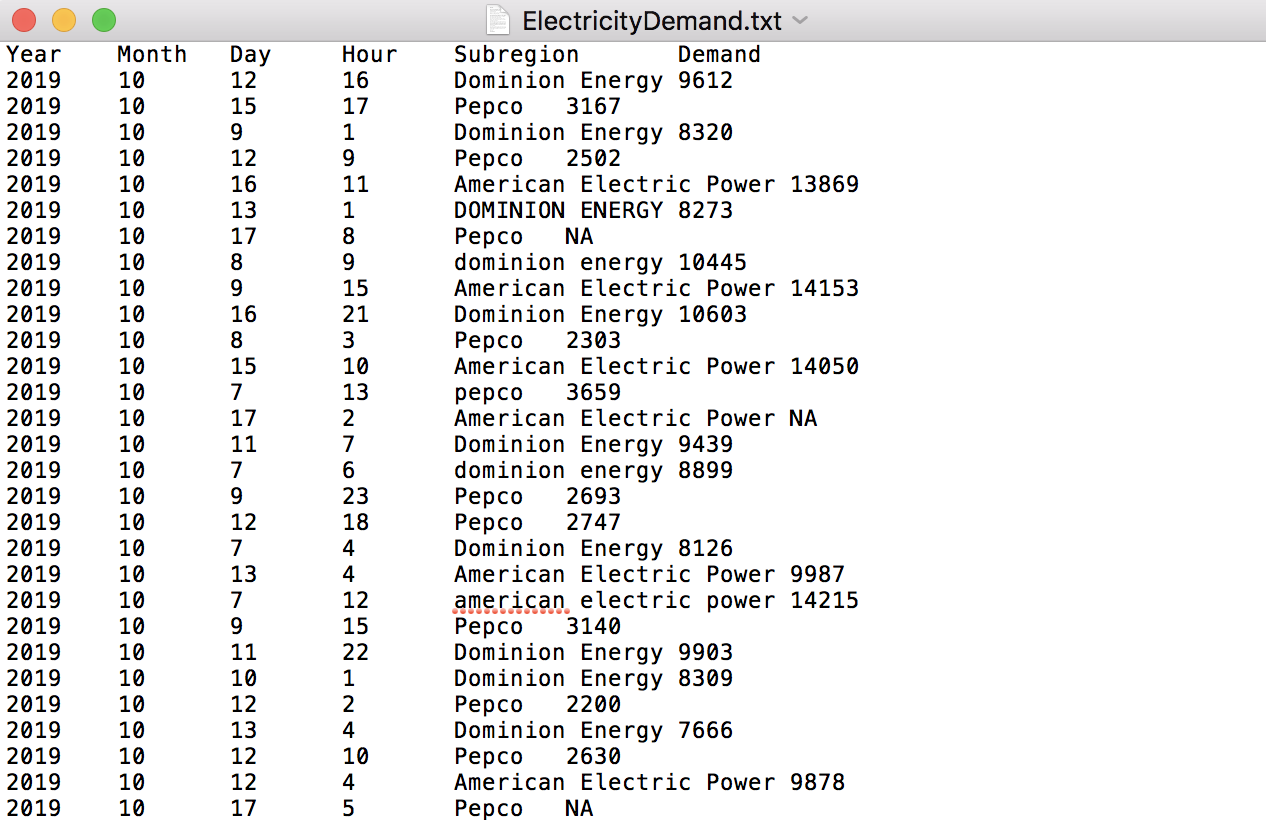
I am attempting to correct a dataset that has multiple different names for the same variable due to differences in capitalization (ie. pepco, Pepco, PEPCO) using stringr.
So far, I have determined the different names the variables are listed under using the following code:
To help us help you, could you please prepare a proper reproducible example (reprex) illustrating your issue? Please have a look at this guide, to see how to create one:
It seems like you have values with similar names, not variables. One way to make sure the values for the Subregion variable are stored the same way would be to use dplyr::mutate and stringr...