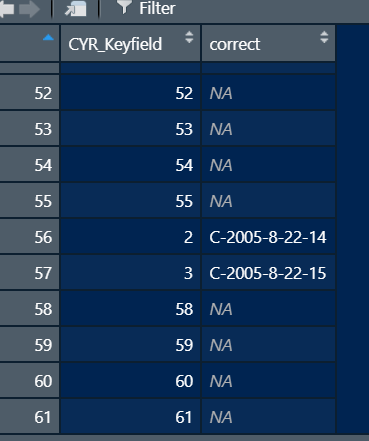
I have a dataframe (called "zeros") containing a column of about 200,000 values with 115 incorrect IDs (called "CYR_Keyfield") scattered throughout the column. I have another dataframe (called "new_ids) with a list of all the incorrect Keyfields from zeros matched with the correct version of the Keyfields (called "correct").
How would I tell R to replace the incorrect CYR_Keyfields in zeros with the values from the "correct" column in the new_ids dataframe? If a CYR_Keyfield value in zeros doesn't match with anything in the new_ids dataframe, I'd like to leave it as is.
I think it nearly worked, but it's replaced the original CYR_Keyfield column values in NewDF with some kind of group of numbers per unique CYR_Keyfield in "correct".
I suspect your original columns are factors and those numbers are the numeric values stored in the factor. Change all of the CYR_Keyfield and correct columns to be characters and my code should work. You can use the as.character() function to do that.