Hello Everyone,
My data set contains about 2000 categorical variables in a single column, please help me with an R code to convert them to numerical variables.
Thanks in Advance!
Hello Everyone,
My data set contains about 2000 categorical variables in a single column, please help me with an R code to convert them to numerical variables.
Thanks in Advance!
its easy, you may want to take advantages of the dplyr library for this:
library(dplyr)
df <- read.csv("your_data_path")
df <- df %>%
mutate_if(is.factor, as.numeric)
are you sure it makes sense to turn the column into numeric?. It seems highly dubious though of course cant guess your context.
Do you mean you have columns that contains character values that you want to be numeric? If you're using an older version of R, these characters will automatically be loaded as factors (aka categorical) when loaded into R (using the point-and-click data loading or the read.csv() function). This was fixed in R 4.0.0.
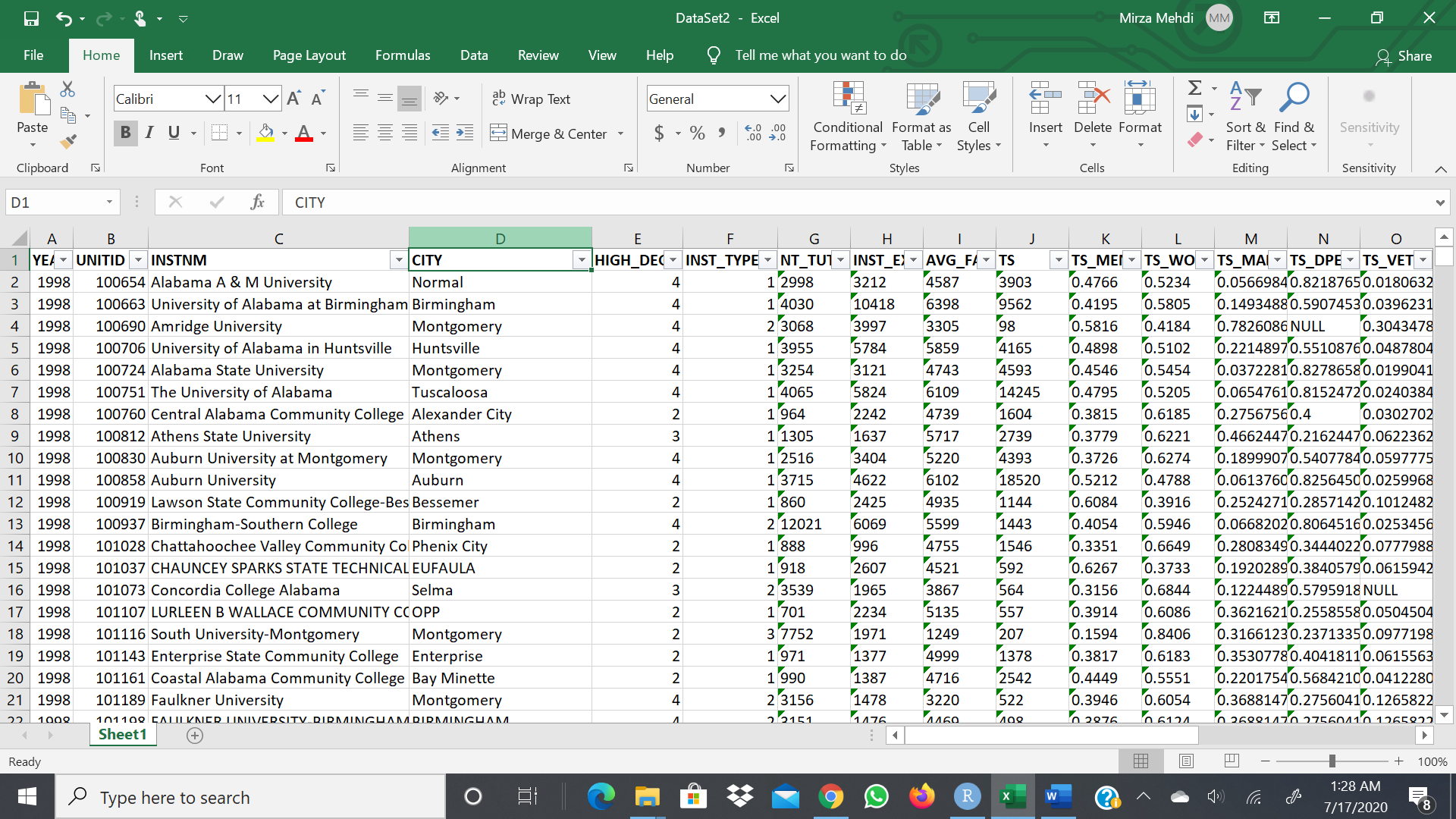
From what I can see, columns from G onward are stored in excel as characters, (the green corner), when they're probably supposed to be numeric, right?
As with everything in R, there are multiple approaches. Here's just one, where we tell R to parse the columns as numbers whilst it's loading the file.
You can specify exactly what type you want the columns to be interpreted as if you load your data using either read_csv() or read_excel() from the {readr} and {readxl} packages respectively (depending on your file format).
In both these functions, the col_types argument lets you specify the type of each column. These work slightly differently in the two functions, but I think your data is in .csv format, which is the easiest style of parsing. Basically, every possible data type is boiled down to a single character. You stick the chosen characters together into a string for your data. For example, if you want your first column to be numeric, your second to be character and your third to be logical, you pass the string "ncl" to the col_types argument ("n" for numeric, "c" for character and "l" for logical). If you have three character columns followed by two integers, a double (aka. decimal) and then another character, you use "ccciidc". See the documentation linked above for the abbreviations.
I'm not sure how many more columns you've got after the O column, so I'm just gonna stop after 15 columns (a 15-character string), but you can make the character string longer as you need following the same conventions. I'm also going to assume your Dataset2.csv file is stored in your current working directory.
install.packages("readr") #You only need to run this once
library(readr)
Dataset2 <- read_csv("Dataset2.csv",col_types = "iicciiiiiiddddd")
Dataset2
If you want the INSTNM and CITY variables to be factors (aka. categorical) rather than characters, just replace the "cc" in the string above with "ff". You can also replace all the "i"s and "d"s with "n", and R will guess whether they need to be integers or doubles.
As a side note, this will (I believe) convert that NULL value in cell O16 to an NA value.
Hi,
I am trying to apply ML algorithms to predict student retention in the higher education data set of USA. There are two columns, the first is Institution Name and the second one City... pls help me with the code in converting these columns to numerical variables...
Thank You!
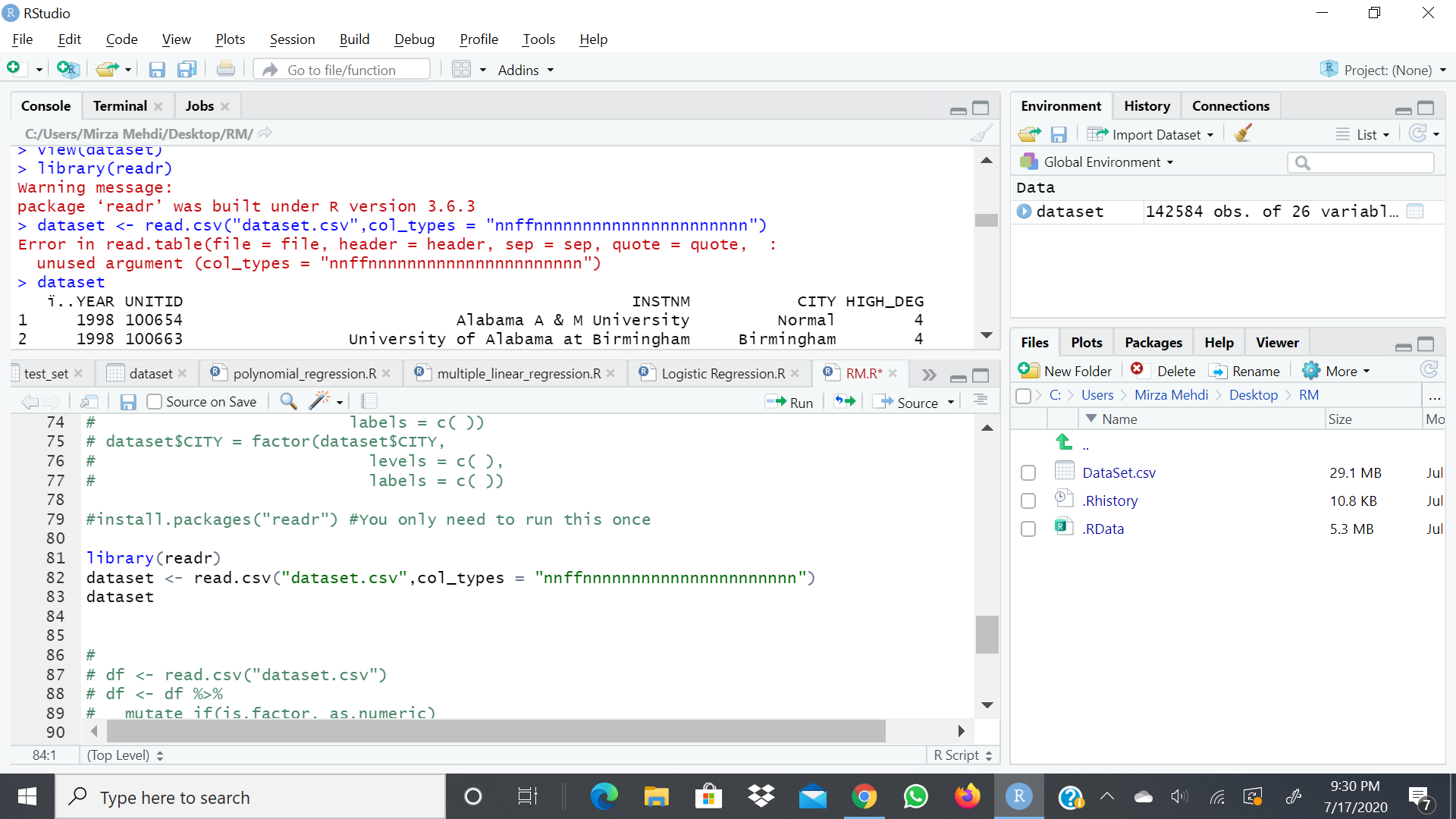
read_csv() and read.csv() are different functions. read.csv() does not want a col_types argument, but read_csv() does. That's where the problem is. Make sure you're using the right symbols and capitalisation (i.e. I believe your file is called Dataset2.csv and not dataset.csv). R is very fickle and you need to be specific
Hi Micheal,
Firstly, thank you so much for trying yo help me... thanks alot... appreciate it!
I have used read_csv but the code still did'nt work. I have also renamed the file now to DataSet.csv
Pls pls help me with the corrections....
My code to fill in the NULL values with mean values is as follows:
dataset$TS_DPEN = ifelse(is.na(dataset$TS_DPEN),
ave(dataset$TS_DPEN, FUN = function(x) mean(x, na.rm = TRUE)),
dataset$TS_DPEN)
Yesterday when i executed, it worked now it is not working... pls help me!
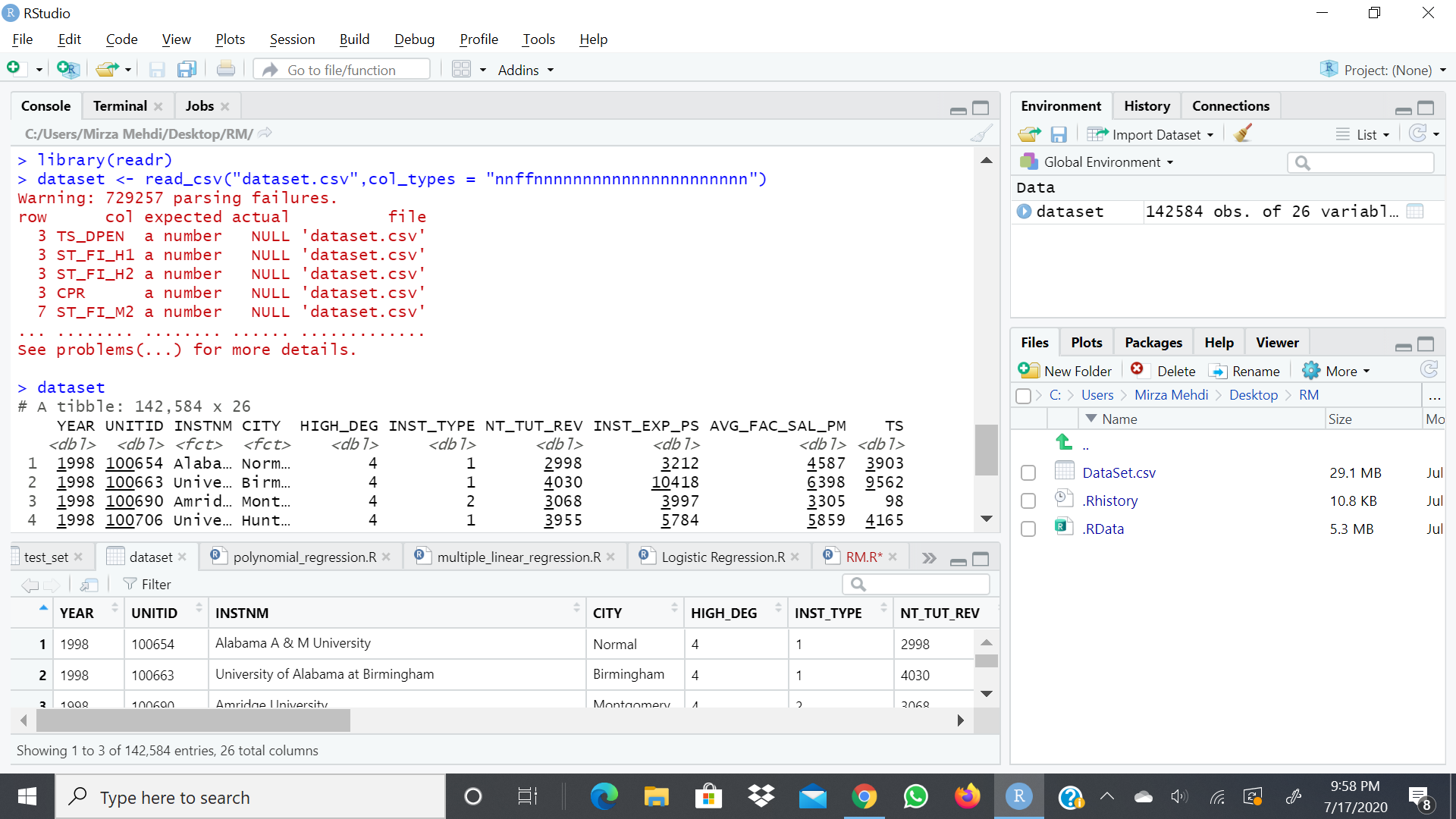
Just checked, if i use read.csv the NULL values are filled in with Mean values...
But, if use read_csv the NULL values do not fill in...
now we have a new error of filling in the NULL values...
also, the categorical values in the respective columns remain the same, they have also not got converted...
pls help me with these issues.... thanks a million!!!
So you want to convert all of the NA values (as parsed by read_csv() from the NULL values) to the mean of the remaining values? The mutate_all() function from the {dplyr} package can run a function on every column in your dataset.
dataset <- mutate_all(dataset,
~if_else(is.na(.),mean(.,na.rm=T),.))
Within the mutate_all() function, we use the ~ symbol which creates "lambda" functions where you can write functions without using function(x). Whatever you want to be your "input", just use a dot, .. So this will calculate the average using mean(.,na.rm=T) if the input value is NA, otherwise, it'll leave it unchanged. Note that I'm using if_else() rather than ifelse()
The other question is regarding turning the actual categorical variables into numbers. Well they're currently stored as factors, which means that behind-the-scenes, they're actually stored as numbers. They just get shown to you ascharacters. This does mean that almost any analysis that you wanna do that requires numeric inputs will work fine.
P.S. You can use "backticks" around code in your posts to make it easier to read. This is part of markup, which is what a lot of online forums (e.g. Reddit) use. On windows, backtick is located on the button to the left if the 1 key (with shift). Use single backticks around inline code or triple backticks on their own lines to write code chunks.
This topic was automatically closed 21 days after the last reply. New replies are no longer allowed.