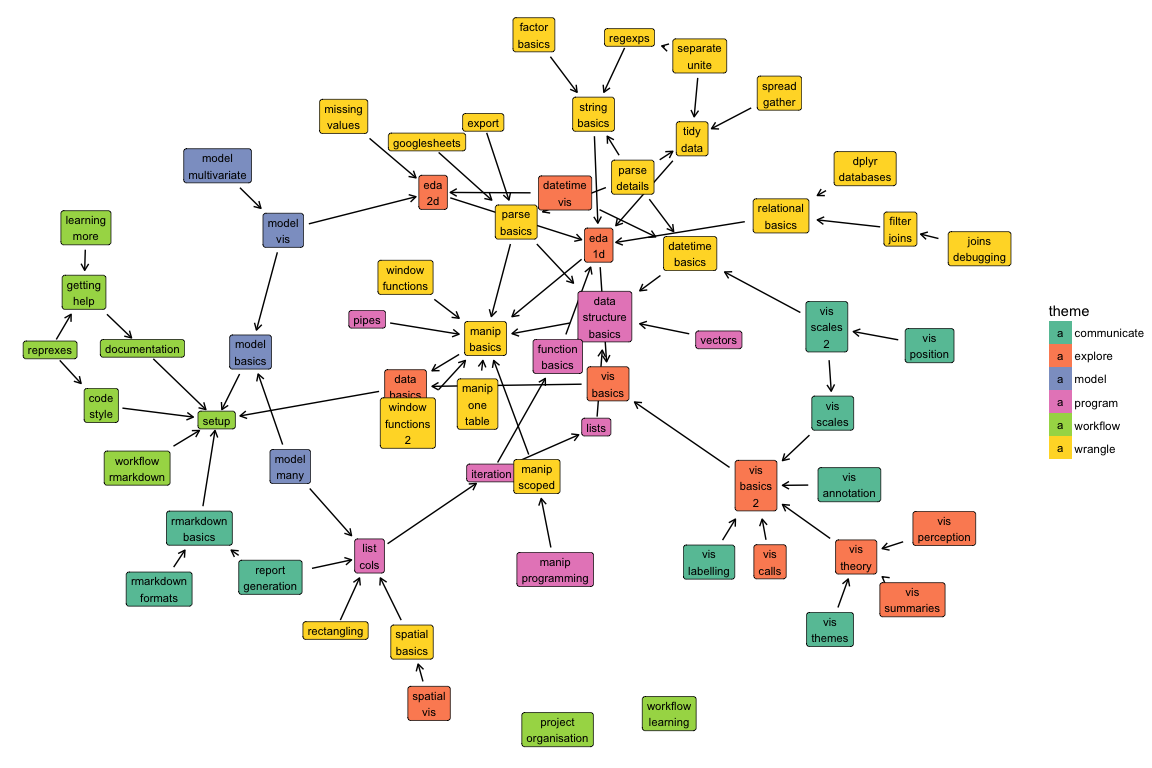
I'd love to have some forum to discuss with other instructors are teaching tidyverse, and particularly anyone using Garrett & Hadley's R4DS book in semester length courses. Is this a good Category for that thread?
For instance, I'm curious how and at what stage such instructors introduce technology such as GitHub & RMarkdown into a course. R4DS text is fascinating to me on many levels, but not least for presenting a comprehensive and compelling ordering for introducing a wide swath of material starting with relatively novice users. However, though it now has a unit on RMarkdown, but introduces this only at the end, and does not attempt to tackle the git / GitHub side of workflows. I've tended to start my students in Rmd notebooks on GitHub.
Would love to hear other ways in which instructors incorporate these materials and in what order they tackle them, and what there reasoning might be for one approach or another. (For instance, I've found the argument to start with visualization as the first thing, rather than, say, data types or control loops like a typical programming course, to be brilliant and very compelling). For reference, the undergraduate course I'm currently teaching around the R4DS text is here: https://espm-157.carlboettiger.info
Thanks!