Hello People,
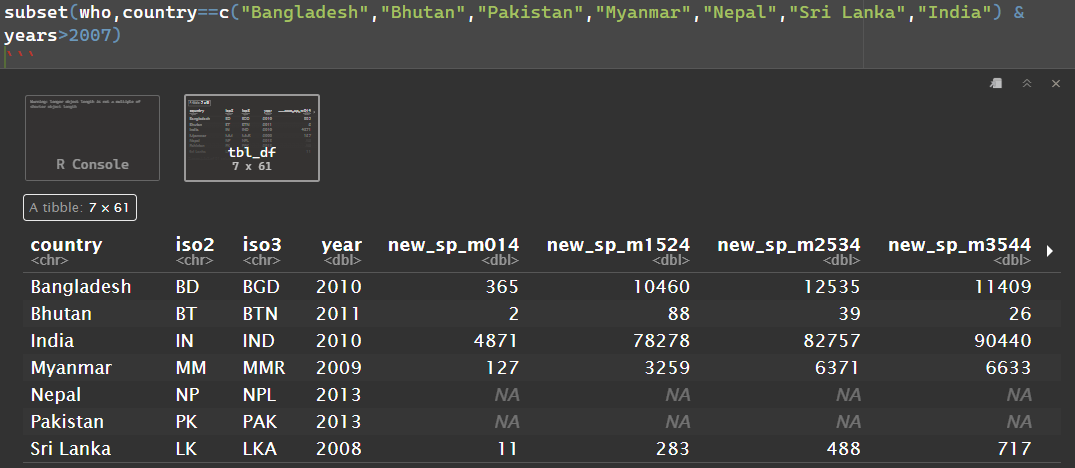
I've been using the subsetting function for a while now, which is giving me confusing results. Now I've used the function on the "who" data under 'tidyr' package.
The codes run fine, but the result is wrong. I've tried it in different combinations, with different countries and years. When I checked the 'who' dataset, it at least has '2013' isolates for every country, but my subset has just picked random 7-8 columns, not showing all the isolates from the specified years but only selective ones. Why is it so? I guess it doesn't handle character vectors well. But how can I subset every isolate from 2005/2007 or above from the specified countries mentioned?
@FJCC Thanks a ton! and noted.
Is there any read on when to use the %in% operator instead of the ' =='?
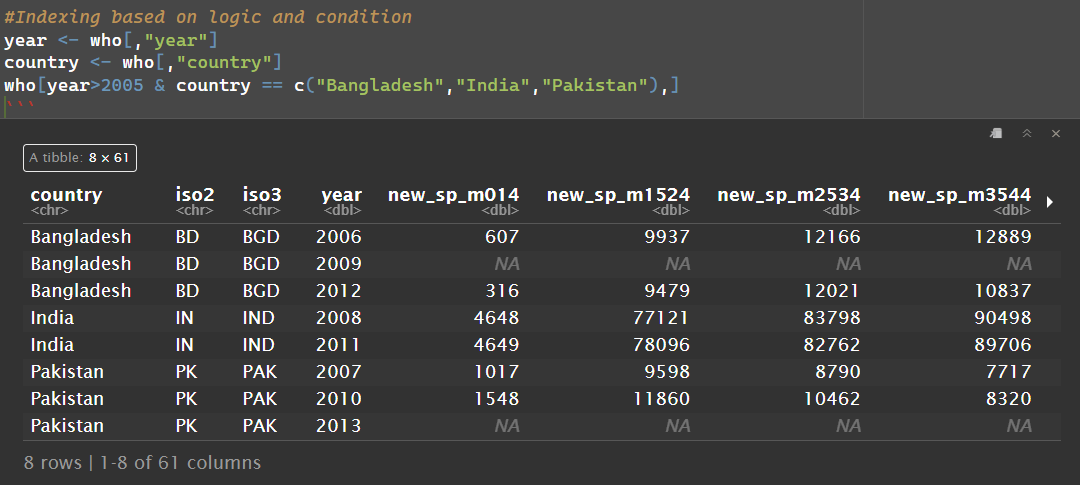
also I tried subsetting through [indexing] but the same %in% solution doesn't work here. Any idea what to do in this case?
returns a data frame and then year > 2005 also returns a data frame and you can't use data frames to index data frames. Use the $ operator to return a vector of values from a data frame column.
year <- who$year
country <- who$country
who[ year > 2005 & country %in% c("Bangladesh","India","Pakistan"),]
The %in% operator returns a single logical value. That is what you need for subsetting, each row gets a TRUE or FALSE. The == operator returns a vector of logical values. I don't know what the subset function does with that but you have shown that it does not work as intended.