# The vector of all male heights in our population is stored in `x`
head(x)
# I Used the `set.seed` function to make sure my answer matches the expected result after random sampling
set.seed(1)
# Define `N` as the number of people measured
N <- 50
# Define `X` as a random sample from our population `x`
X <- sample(x,N, replace = TRUE)
# Define `se` as the standard error of the estimate. Print this value to the console.
se <- sd(X)/sqrt(N)
# Construct a 95% confidence interval for the population average based on our sample. Save the lower and then the upper confidence interval to a variable called `ci`.
ci <- c(X - qnorm(0.975) * se, X + qnorm(0.975) * se)
Trying to figure out how to apply the mean() to find the average of the sample.
If I understand you correctly, I think you should be able to use mean(X). You might want to avoid using x and X, as this makes your code prone to simple errors.
yes, you are right, I need mean(X) (the avg of the sample) just not sure where to add it. I think it goes on the sample() line, not in the sample() just on the line, Ive tried it before and after the sample(), on the other lines as well, but it faults. does it go on the sample() line ?
The formula for a one sample mean confidence interval is
sample mean \pm critical value * standard error
The sample mean in your case is mean(X) (though I agree that using a different variable name for the sample could make things clearer).
The standard error is indeed calculated as the standard deviation of the sample divided by the square root of the sample size. (As a side note, it is more customary to use n instead of N for sample size.)
In your confidence interval calculation you should be adding/subtracting the margin of error to mean(X).
For the critical value you might consider using qt(0.975, df = N - 1), though with a sample size of 50 the difference between using Z or T would be small.
2 Likes
X <- sample(x,N, replace = TRUE)
mean(X)
My understanding is to just get the mean of X , mean(X) , like this. when I do this it throws my se_hat calculation off. ive tried getting the mean on the sample() line but that didnt work either. where on which line to get the mean(X) ?
is X <- mean(X) valid and what I need ?
X <- mean(X) is changing the definition of X so that instead of holding your sample values, it now just holds the single mean value.
You can use mean(X) anywhere you want without assigning a name to it. For example:
mean(X) * 2
will print twice whatever the mean of X is to the console.
If you want to give mean(X) a name (so that it appears as an object in your environment that you can re-use), you should give it a new name, e.g.
mean_X <- mean(X)
Running mean(X) on its own shouldn't affect any other code — it just prints the result to the console. If, however, you've used X <- mean(X) to redefine X as the mean instead of the sampled values, then yes, that will affect any other lines of code that refer to X.
is my sample( ) valid ?
can i make it so that X not only holds the sample values but the mean of them at the same time ?
You could make a list that stores both:
x <- rnorm(200, mean = 65)
X <- list(sample = sample(x, 50, replace = TRUE))
X$mean <- mean(X$sample)
X
#> $sample
#> [1] 64.42874 65.13998 65.13584 64.30308 64.20224 65.74763 64.59870
#> [8] 65.13584 65.69836 65.17089 65.13584 63.22821 64.76566 65.57795
#> [15] 65.58011 65.82964 65.54891 64.64883 63.69090 63.69090 65.43191
#> [22] 66.05664 65.82151 64.50164 64.79559 65.35930 64.50164 65.88504
#> [29] 65.94536 65.37531 65.58011 65.22287 66.47578 64.59088 65.82151
#> [36] 62.99662 67.55957 63.73857 65.85067 64.38363 64.05551 63.94060
#> [43] 64.95667 65.58011 63.37124 63.01764 64.59088 65.27352 65.15911
#> [50] 64.43312
#>
#> $mean
#> [1] 64.95062
Created on 2018-05-15 by the reprex package (v0.2.0).
(I had to invent my own x, since I don't have access to yours)
To access the sample part of X, you'd use X$sample, and to access the mean part, you'd use X$mean... but I'm not sure I understand why you'd want to do this?
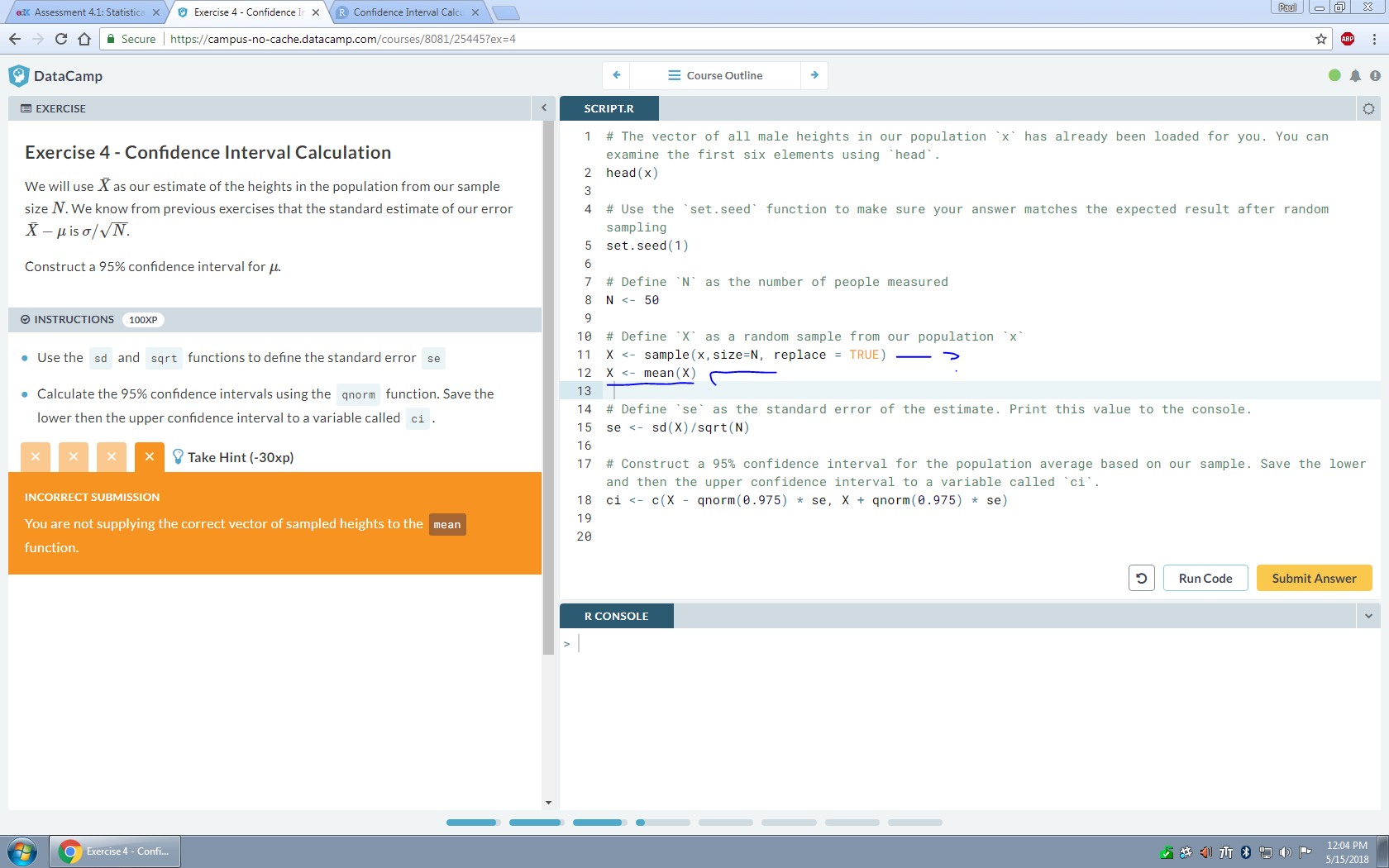
i did not want to load a screenshot, but it might be the best way to show exactly what i am trying to do.
Ah, I see. I don't think that the scoring robot is expecting you to redefine X as the mean.
I think your best bet is to go back and re-read @mine's post about the correct way to calculate a one sample mean confidence interval, and then keep in mind the bit I said about how you can use mean(X) anywhere you want without giving it a special name.
i tried wrapping mean() around both "X" in the ci object defintion and it didnt work. is that what @mine was hinting at ?
Yup. Two further hints:
- Make sure that line redefining
Xis gone. - Consider order of operations — you might test this for yourself with this mini-problem:
# Does R say the result is 7 or 9?
1 + 2 * 3
# How can we make sure the result is 9?
by using ( ), ^, *,/,-,+ in the right order of operations to give the desired flow and output.
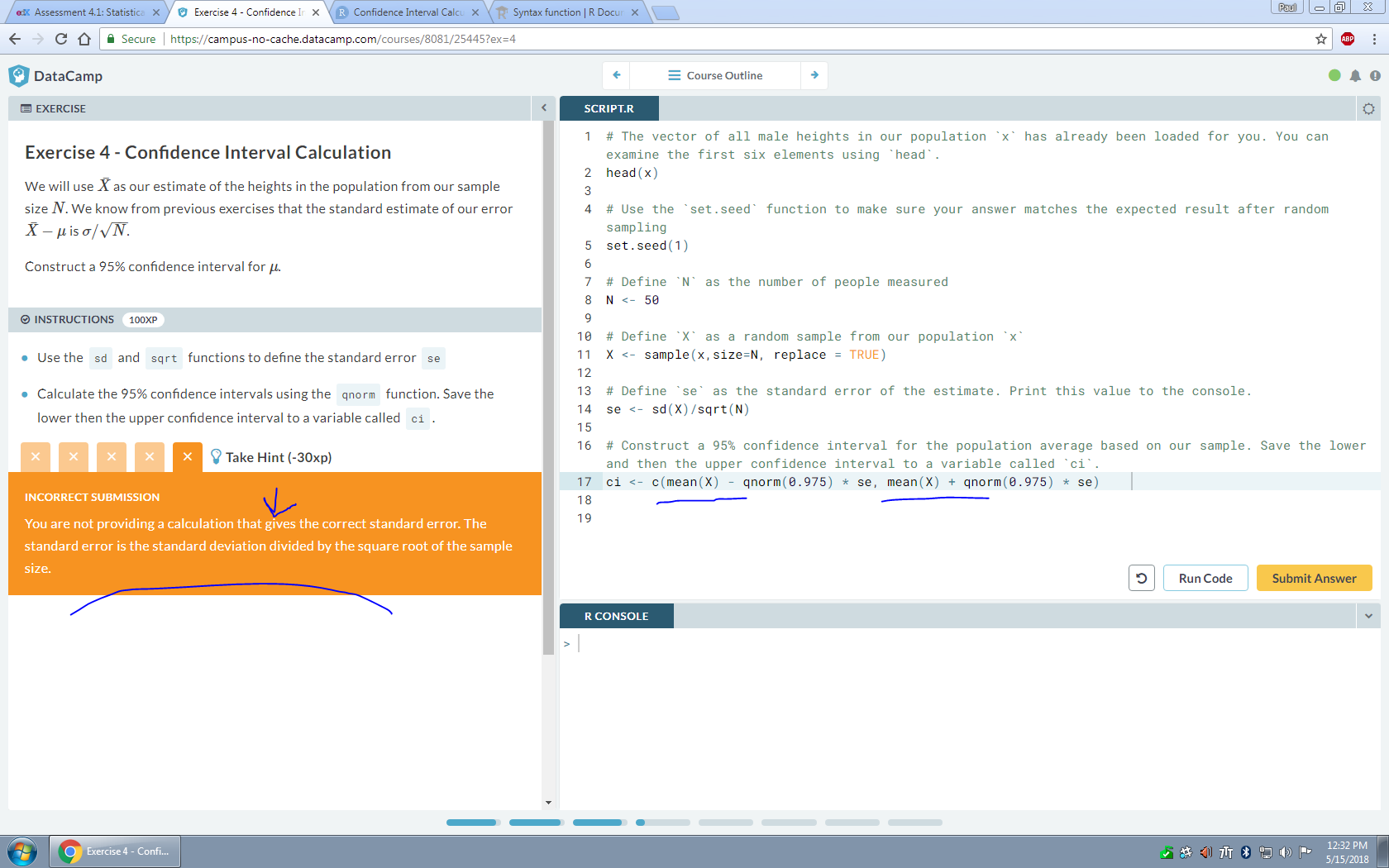
i dont understand why using mean(X) in the ci object changes X to the point that my se object becomes invalid
Hmm, yeah, the problem with automated scoring is that it can't anticipate everything, so sometimes you feel like you're jumping through hoops to get it to accept an answer. As far as I can tell, the scoring robot is no longer objecting to anything about your ci — it's complaining about the part where you define se (line 14).
The only thing sticking out to me about the se line is that the instructions asked you to both define and print the value to the console. You did the definition part, but you didn't print anything. Does it accept your answer if you print?