Hello,
I have been running lmer models and have been using backwards elimination to remove the least significant factors from my model. I have then been comparing the models using the following code:
anova (model_1 , model_2, test = "Chisq")
to determine whether removal of the none significantvariables influences the overall model.
Normally the result is the same no matter which order I place the models in the above equation. ie:
anova (model_1 , model_2, test = "Chisq")
anova (model_2 , model_1, test = "Chisq")
always yield the same result. I have noticed in books with examples that the order doesn't seem to matter. The authors will put the models in the equation with no particular order (ie: there is never a trend that the more complex model goes first for example).
Yesterday I compared these two models (I have also re-started my laptop, cleared my history and re-started running the models today and I am still receiving the same result). I received this result but do not know what it means:
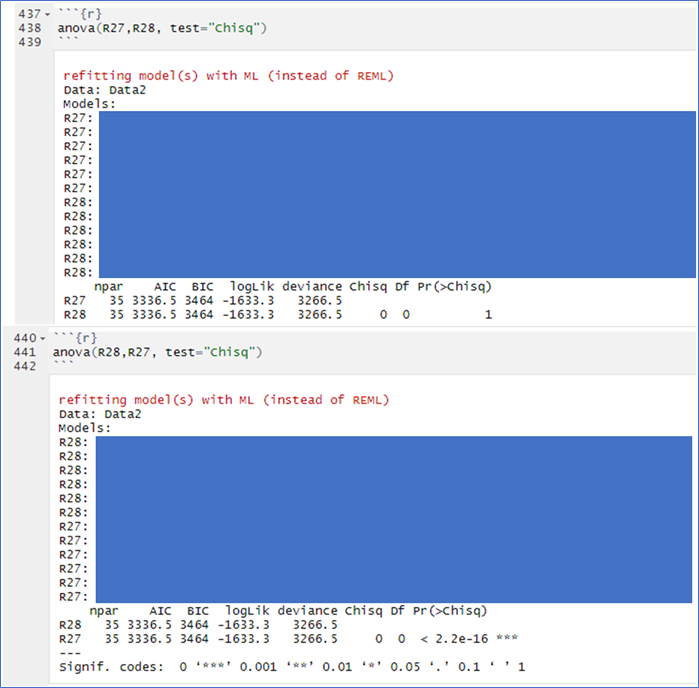
As you can see one output suggests there is no difference between the models whilst the other output suggests there is a highly significant difference. I have never seen this before and I am not sure what it means. The AIC and BIC are the same in both. There is only one variable difference between R27 and R28 here (R27 more complex).
I usually receive results like this where both the p values associated with each model are the same (AIC and BIC also the same here; there is only one variable difference between R27 and R28 here however, this variable is different to the above example, R27 more complex model):

Or like this where the p value remains with one of the models no matter which order the models are entered into the equation (AIC and BIC are different; only one variable difference between R28 and R29, R28 is the more complex model):
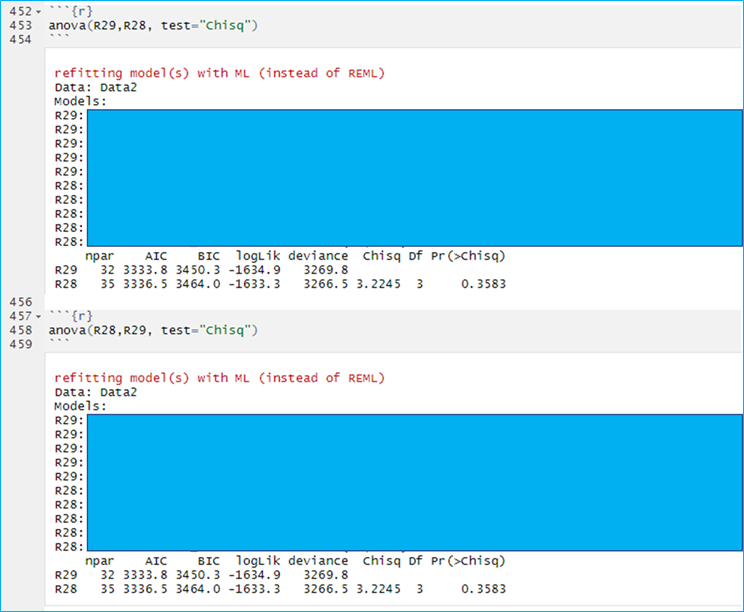
I have no clue what this means and am at a loss at what search term to try and google to find the answer, though I have tried many variations without success. The only examples as I've mentioned above seem to use any order. Any advice or suggestions as to what this means or what could be going wrong would be greatly appreciated.
Thanks!